Bayesian Spatial Models: A Pedagogical Walkthrough¶
This notebook demonstrates all five models currently implemented in bayespecon:
SLX
SAR
SEM
SDM
SDEM
Each section explains the model idea, fits the model, and inspects posterior summaries and spatial effects.
Conceptual Roadmap¶
Let \(W\) denote the spatial weights matrix and \(WX\) the spatial lag of covariates.
SLX: \(y = X\beta + WX\theta + \epsilon\)
SAR: \(y = \rho Wy + X\beta + \epsilon\)
SEM: \(y = X\beta + u\), \(u = \lambda Wu + \epsilon\)
SDM: \(y = \rho Wy + X\beta + WX\theta + \epsilon\)
SDEM: \(y = X\beta + WX\theta + u\), \(u = \lambda Wu + \epsilon\)
In bayespecon, all models accept either:
formula mode:
model_class(formula=..., data=..., W=...), ormatrix mode:
model_class(y=..., X=..., W=...).
import arviz as az
import geodatasets
import geopandas as gpd
import matplotlib.pyplot as plt
import pandas as pd
from libpysal.graph import Graph
from bayespecon import OLS, SAR, SDEM, SDM, SEM, SLX
from bayespecon.diagnostics.bayesfactor import bayes_factor_compare_models
az.style.use("arviz-white")
/home/runner/micromamba/envs/test/lib/python3.14/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
# Load sample spatial dataset
gdf = gpd.read_file(geodatasets.data.geoda.airbnb.url)
xcols = ["poverty", "rev_rating", "num_spots", "crowded"]
ycol = "price_pp"
gdf = gdf.dropna(subset=xcols + [ycol]).copy()
# Build contiguity graph (queen)
W = Graph.build_contiguity(gdf, rook=False).transform("r")
print(f"Observations: {len(gdf)}")
print(f"Predictors: {xcols}")
Observations: 67
Predictors: ['poverty', 'rev_rating', 'num_spots', 'crowded']
Helper Functions
To keep each model section focused, we use utility functions to:
fit with consistent MCMC settings,
print posterior summaries,
tabulate direct/indirect/total effects.
For a quick pedagogical run, we use small draw counts. Increase these for real inference.
def fit_and_report(model_cls, formula, data, W, draws=400, tune=400, chains=4, seed=42):
"""Fit a spatial model and return (model, summary, effects_df).
Uses minimal MCMC settings for pedagogical demonstration.
Increase draws/tune for real analyses.
"""
model = model_cls(formula=formula, data=data, W=W, logdet_method="eigenvalue")
model.fit(
draws=draws,
tune=tune,
chains=chains,
target_accept=0.9,
random_seed=seed,
progressbar=False,
idata_kwargs={"log_likelihood": True},
)
summary = model.summary(round_to=3)
effects_df = pd.DataFrame(model.spatial_effects())
return model, summary, effects_df
Convergence Diagnostics Helper
For each fitted model, we will inspect:
r_hat(target close to 1.00)effective sample sizes (
ess_bulk,ess_tail)trace plots for key parameters.
def diagnostics_table(idata, var_names):
"""Show key MCMC diagnostics for the given parameters."""
cols = ["mean", "sd", "ess_bulk", "ess_tail", "r_hat"]
return az.summary(idata, var_names=var_names, round_to=3)[cols]
def show_trace(idata, var_names, title):
"""Plot trace plots for the given parameters."""
az.plot_trace(idata, var_names=var_names)
plt.suptitle(title, y=1.02)
plt.tight_layout()
plt.show()
Models¶
0) OLS: What could go wrong?¶
Model:
ols = OLS(
formula="price_pp ~ poverty + rev_rating + num_spots + crowded",
data=gdf,
W=W,
)
olsfit = ols.fit(
draws=400,
tune=400,
chains=4,
target_accept=0.9,
random_seed=42,
progressbar=False,
idata_kwargs={"log_likelihood": True},
)
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 2 jobs)
NUTS: [beta, sigma2]
Sampling 4 chains for 400 tune and 400 draw iterations (1_600 + 1_600 draws total) took 14 seconds.
ols.summary()
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| Intercept | 35.251 | 59.870 | -74.861 | 144.271 | 2.419 | 1.252 | 614.0 | 952.0 | 1.0 |
| poverty | 0.204 | 0.328 | -0.455 | 0.786 | 0.010 | 0.008 | 1128.0 | 999.0 | 1.0 |
| rev_rating | 0.372 | 0.635 | -0.823 | 1.532 | 0.025 | 0.013 | 622.0 | 930.0 | 1.0 |
| num_spots | 0.121 | 0.023 | 0.076 | 0.161 | 0.001 | 0.001 | 1037.0 | 1106.0 | 1.0 |
| crowded | -2.175 | 0.960 | -4.038 | -0.447 | 0.027 | 0.026 | 1222.0 | 873.0 | 1.0 |
| sigma2 | 753.603 | 139.878 | 512.958 | 1016.011 | 4.332 | 4.728 | 1075.0 | 1066.0 | 1.0 |
| sigma | 27.340 | 2.478 | 22.649 | 31.875 | 0.076 | 0.074 | 1075.0 | 1066.0 | 1.0 |
1) SLX: Spatially Lagged Covariates Only¶
Model:
Interpretation:
betacaptures local covariate effects.thetacaptures neighbor-covariate spillovers.No spatial lag on \(y\), so no autoregressive propagation through outcomes.
slx, summary_slx, effects_slx = fit_and_report(
SLX,
formula="price_pp ~ poverty + rev_rating + num_spots + crowded",
data=gdf,
W=W,
)
display(summary_slx)
display(effects_slx)
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 2 jobs)
NUTS: [beta, sigma2]
Sampling 4 chains for 400 tune and 400 draw iterations (1_600 + 1_600 draws total) took 17 seconds.
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| Intercept | 90.613 | 77.431 | -50.586 | 230.823 | 2.852 | 1.845 | 732.657 | 918.725 | 1.005 |
| poverty | -0.659 | 0.472 | -1.581 | 0.178 | 0.015 | 0.013 | 951.327 | 892.080 | 1.003 |
| rev_rating | 0.592 | 0.773 | -0.899 | 1.996 | 0.024 | 0.018 | 1069.421 | 1194.587 | 1.000 |
| num_spots | 0.021 | 0.032 | -0.042 | 0.077 | 0.001 | 0.001 | 1017.610 | 1030.384 | 1.000 |
| crowded | -0.953 | 1.188 | -3.262 | 1.167 | 0.038 | 0.031 | 993.532 | 933.014 | 1.005 |
| W*poverty | 1.347 | 0.634 | 0.170 | 2.523 | 0.020 | 0.018 | 1023.534 | 876.226 | 1.005 |
| W*rev_rating | -0.971 | 0.967 | -2.847 | 0.674 | 0.031 | 0.025 | 944.270 | 951.677 | 1.004 |
| W*num_spots | 0.196 | 0.047 | 0.109 | 0.285 | 0.001 | 0.001 | 1226.908 | 870.559 | 1.001 |
| W*crowded | -1.797 | 1.628 | -5.344 | 0.914 | 0.051 | 0.040 | 1007.256 | 1074.373 | 1.004 |
| sigma2 | 602.079 | 108.106 | 422.715 | 813.502 | 3.064 | 3.316 | 1197.693 | 1052.758 | 1.002 |
| sigma | 24.443 | 2.155 | 20.560 | 28.522 | 0.061 | 0.061 | 1197.693 | 1052.758 | 1.002 |
| direct | direct_ci_lower | direct_ci_upper | direct_pvalue | indirect | indirect_ci_lower | indirect_ci_upper | indirect_pvalue | total | total_ci_lower | total_ci_upper | total_pvalue | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| variable | ||||||||||||
| poverty | -0.659052 | -1.601593 | 0.231882 | 0.15125 | 1.346843 | 0.117417 | 2.594038 | 0.02750 | 0.687791 | -0.110299 | 1.468234 | 0.09500 |
| rev_rating | 0.592169 | -0.896319 | 2.096830 | 0.44625 | -0.970656 | -2.797226 | 0.905773 | 0.35125 | -0.378487 | -1.908068 | 1.227827 | 0.65125 |
| num_spots | 0.020669 | -0.041834 | 0.083592 | 0.52625 | 0.196372 | 0.102324 | 0.292509 | 0.00000 | 0.217041 | 0.156992 | 0.278706 | 0.00000 |
| crowded | -0.952527 | -3.333149 | 1.339526 | 0.43375 | -1.797385 | -5.219024 | 1.347702 | 0.25375 | -2.749912 | -5.281017 | -0.198711 | 0.02875 |
az.plot_forest(slx.inference_data)
display(diagnostics_table(slx.inference_data, ["beta", "sigma"]))
show_trace(slx.inference_data, ["sigma"], "SLX Trace: sigma")
| mean | sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|
| beta[Intercept] | 90.613 | 77.431 | 732.657 | 918.725 | 1.005 |
| beta[poverty] | -0.659 | 0.472 | 951.327 | 892.080 | 1.003 |
| beta[rev_rating] | 0.592 | 0.773 | 1069.421 | 1194.587 | 1.000 |
| beta[num_spots] | 0.021 | 0.032 | 1017.610 | 1030.384 | 1.000 |
| beta[crowded] | -0.953 | 1.188 | 993.532 | 933.014 | 1.005 |
| beta[W*poverty] | 1.347 | 0.634 | 1023.534 | 876.226 | 1.005 |
| beta[W*rev_rating] | -0.971 | 0.967 | 944.270 | 951.677 | 1.004 |
| beta[W*num_spots] | 0.196 | 0.047 | 1226.908 | 870.559 | 1.001 |
| beta[W*crowded] | -1.797 | 1.628 | 1007.256 | 1074.373 | 1.004 |
| sigma | 24.443 | 2.155 | 1197.693 | 1052.758 | 1.002 |
/tmp/ipykernel_7302/3581438262.py:11: UserWarning: The figure layout has changed to tight
plt.tight_layout()


2) SAR: Spatial Lag of Outcome¶
Model:
Interpretation:
\(\rho\) controls feedback from neighboring outcomes.
Effects are amplified through \((I - \rho W)^{-1}\), so direct and indirect impacts differ from raw \(\beta\).
sar, summary_sar, effects_sar = fit_and_report(
SAR,
formula="price_pp ~ poverty + rev_rating + num_spots + crowded",
data=gdf,
W=W,
)
summary_sar
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| rho | 0.421 | 0.145 | 0.146 | 0.678 | 0.004 | 0.004 | 1590.247 | 1184.079 | 1.000 |
| sigma | 25.386 | 2.359 | 21.530 | 29.974 | 0.062 | 0.049 | 1464.873 | 1571.805 | 0.999 |
| sigma2 | 649.990 | 123.329 | 441.912 | 873.378 | 3.217 | 3.083 | 1464.873 | 1571.805 | 0.999 |
| Intercept | 14.767 | 61.025 | -99.183 | 130.590 | 1.620 | 1.100 | 1414.628 | 1400.482 | 1.003 |
| poverty | 0.023 | 0.316 | -0.546 | 0.596 | 0.008 | 0.006 | 1532.303 | 1457.932 | 0.999 |
| rev_rating | 0.310 | 0.646 | -0.955 | 1.501 | 0.017 | 0.012 | 1363.433 | 1486.916 | 1.003 |
| num_spots | 0.081 | 0.026 | 0.031 | 0.131 | 0.001 | 0.001 | 1652.805 | 1258.488 | 0.999 |
| crowded | -1.699 | 0.902 | -3.446 | -0.136 | 0.023 | 0.017 | 1536.060 | 1394.467 | 1.000 |
effects_sar
| direct | direct_ci_lower | direct_ci_upper | direct_pvalue | indirect | indirect_ci_lower | indirect_ci_upper | indirect_pvalue | total | total_ci_lower | total_ci_upper | total_pvalue | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| variable | ||||||||||||
| poverty | 0.024697 | -0.613046 | 0.677931 | 0.96375 | 0.021962 | -0.581090 | 0.681887 | 0.96000 | 0.046659 | -1.167219 | 1.331629 | 0.96375 |
| rev_rating | 0.328718 | -1.077799 | 1.649850 | 0.60875 | 0.247220 | -0.903171 | 1.642584 | 0.60750 | 0.575938 | -1.919240 | 3.027178 | 0.60875 |
| num_spots | 0.085493 | 0.030706 | 0.145186 | 0.00125 | 0.063961 | 0.007254 | 0.179294 | 0.00500 | 0.149453 | 0.046372 | 0.318456 | 0.00125 |
| crowded | -1.802522 | -3.643787 | 0.081732 | 0.06000 | -1.360454 | -4.614532 | 0.043354 | 0.06375 | -3.162976 | -7.891553 | 0.129498 | 0.06000 |
az.plot_forest(sar.inference_data)
display(diagnostics_table(sar.inference_data, ["rho", "beta", "sigma"]))
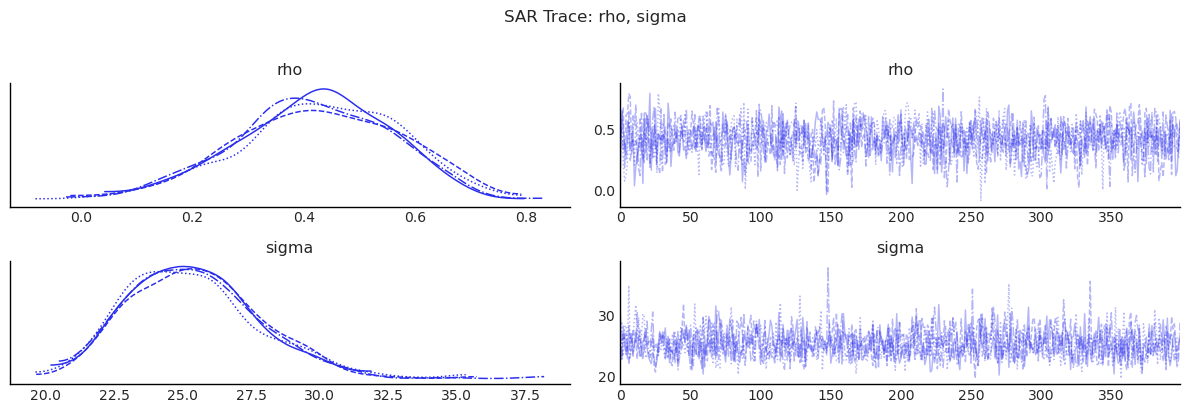
show_trace(sar.inference_data, ["rho", "sigma"], "SAR Trace: rho, sigma")
| mean | sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|
| rho | 0.421 | 0.145 | 1590.247 | 1184.079 | 1.000 |
| beta[Intercept] | 14.767 | 61.025 | 1414.628 | 1400.482 | 1.003 |
| beta[poverty] | 0.023 | 0.316 | 1532.303 | 1457.932 | 0.999 |
| beta[rev_rating] | 0.310 | 0.646 | 1363.433 | 1486.916 | 1.003 |
| beta[num_spots] | 0.081 | 0.026 | 1652.805 | 1258.488 | 0.999 |
| beta[crowded] | -1.699 | 0.902 | 1536.060 | 1394.467 | 1.000 |
| sigma | 25.386 | 2.359 | 1464.873 | 1571.805 | 0.999 |
/tmp/ipykernel_7302/3581438262.py:11: UserWarning: The figure layout has changed to tight
plt.tight_layout()

3) SEM: Spatial Correlation in Errors¶
Model:
Interpretation:
Spatial dependence is moved to latent shocks rather than outcome feedback.
Useful when omitted spatial factors induce correlated residuals.
sem, summary_sem, effects_sem = fit_and_report(
SEM,
formula="price_pp ~ poverty + rev_rating + num_spots + crowded",
data=gdf,
W=W,
)
display(summary_sem)
display(effects_sem)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| lam | 0.490 | 0.184 | 0.133 | 0.805 | 0.005 | 0.005 | 1508.653 | 918.977 | 1.002 |
| sigma | 25.856 | 2.362 | 21.899 | 30.401 | 0.061 | 0.048 | 1479.718 | 1570.485 | 1.001 |
| sigma2 | 674.083 | 125.181 | 457.157 | 898.309 | 3.254 | 2.976 | 1479.718 | 1570.485 | 1.001 |
| Intercept | 19.475 | 58.940 | -96.823 | 130.438 | 1.557 | 1.182 | 1451.461 | 1156.616 | 1.000 |
| poverty | -0.165 | 0.440 | -0.958 | 0.670 | 0.011 | 0.008 | 1521.688 | 1706.191 | 1.002 |
| rev_rating | 0.630 | 0.628 | -0.577 | 1.803 | 0.016 | 0.012 | 1472.748 | 1257.599 | 1.001 |
| num_spots | 0.073 | 0.036 | 0.009 | 0.144 | 0.001 | 0.001 | 1375.208 | 1377.750 | 1.001 |
| crowded | -1.795 | 1.146 | -3.953 | 0.284 | 0.029 | 0.021 | 1560.680 | 1598.345 | 0.999 |
| direct | direct_ci_lower | direct_ci_upper | direct_pvalue | indirect | indirect_ci_lower | indirect_ci_upper | indirect_pvalue | total | total_ci_lower | total_ci_upper | total_pvalue | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| variable | ||||||||||||
| poverty | -0.164892 | -1.107434 | 0.644466 | 0.74625 | 0.0 | 0.0 | 0.0 | 0.0 | -0.164892 | -1.107434 | 0.644466 | 0.74625 |
| rev_rating | 0.630048 | -0.643103 | 1.878016 | 0.29375 | 0.0 | 0.0 | 0.0 | 0.0 | 0.630048 | -0.643103 | 1.878016 | 0.29375 |
| num_spots | 0.073165 | 0.000840 | 0.141194 | 0.04750 | 0.0 | 0.0 | 0.0 | 0.0 | 0.073165 | 0.000840 | 0.141194 | 0.04750 |
| crowded | -1.794689 | -3.998429 | 0.430650 | 0.11250 | 0.0 | 0.0 | 0.0 | 0.0 | -1.794689 | -3.998429 | 0.430650 | 0.11250 |
az.plot_forest(sem.inference_data)
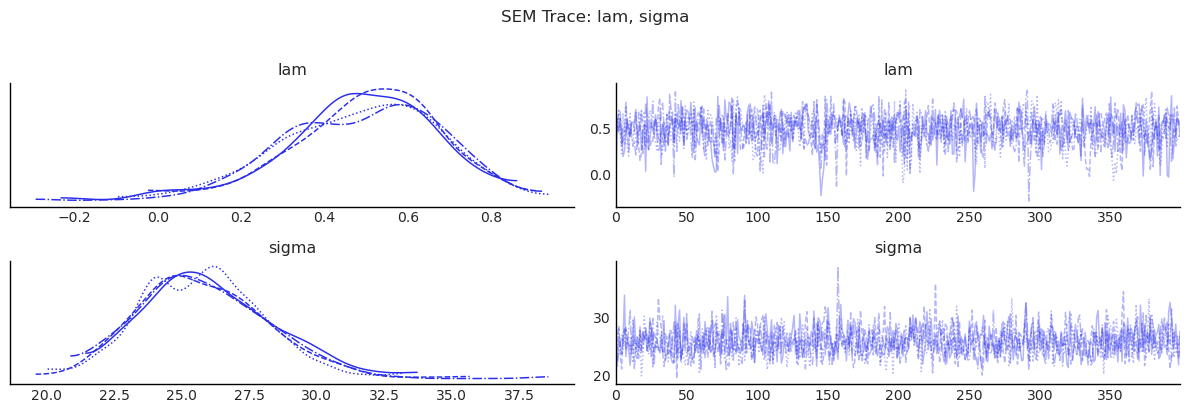
display(diagnostics_table(sem.inference_data, ["lam", "beta", "sigma"]))
show_trace(sem.inference_data, ["lam", "sigma"], "SEM Trace: lam, sigma")
| mean | sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|
| lam | 0.490 | 0.184 | 1508.653 | 918.977 | 1.002 |
| beta[Intercept] | 19.475 | 58.940 | 1451.461 | 1156.616 | 1.000 |
| beta[poverty] | -0.165 | 0.440 | 1521.688 | 1706.191 | 1.002 |
| beta[rev_rating] | 0.630 | 0.628 | 1472.748 | 1257.599 | 1.001 |
| beta[num_spots] | 0.073 | 0.036 | 1375.208 | 1377.750 | 1.001 |
| beta[crowded] | -1.795 | 1.146 | 1560.680 | 1598.345 | 0.999 |
| sigma | 25.856 | 2.362 | 1479.718 | 1570.485 | 1.001 |
/tmp/ipykernel_7302/3581438262.py:11: UserWarning: The figure layout has changed to tight
plt.tight_layout()

4) SDM: SAR + SLX¶
Model:
Interpretation:
Includes both outcome feedback and neighbor-covariate channels.
Often used as a flexible nesting model for SAR/SLX.
sdm, summary_sdm, effects_sdm = fit_and_report(
SDM,
formula="price_pp ~ poverty + rev_rating + num_spots + crowded",
data=gdf,
W=W,
)
display(summary_sdm)
display(effects_sdm)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| rho | 0.223 | 0.171 | -0.107 | 0.519 | 0.004 | 0.004 | 1721.619 | 1299.748 | 1.000 |
| sigma | 24.095 | 2.253 | 20.198 | 28.430 | 0.065 | 0.051 | 1229.013 | 1530.625 | 1.001 |
| sigma2 | 585.647 | 112.249 | 407.965 | 808.244 | 3.221 | 3.080 | 1229.013 | 1530.625 | 1.001 |
| Intercept | 87.065 | 78.479 | -57.977 | 232.494 | 1.929 | 1.377 | 1647.108 | 1361.040 | 0.999 |
| poverty | -0.643 | 0.469 | -1.443 | 0.272 | 0.011 | 0.009 | 1777.358 | 1611.313 | 1.000 |
| rev_rating | 0.688 | 0.770 | -0.693 | 2.234 | 0.020 | 0.015 | 1474.167 | 1515.338 | 1.000 |
| num_spots | 0.019 | 0.031 | -0.036 | 0.081 | 0.001 | 0.001 | 1849.856 | 1659.838 | 1.000 |
| crowded | -0.998 | 1.134 | -3.131 | 1.079 | 0.028 | 0.022 | 1640.344 | 1335.392 | 1.003 |
| W*poverty | 1.173 | 0.632 | 0.018 | 2.354 | 0.016 | 0.012 | 1609.890 | 1571.707 | 1.000 |
| W*rev_rating | -1.168 | 0.976 | -2.987 | 0.696 | 0.023 | 0.019 | 1791.192 | 1595.063 | 1.000 |
| W*num_spots | 0.162 | 0.052 | 0.061 | 0.257 | 0.001 | 0.001 | 1706.260 | 1534.498 | 0.999 |
| W*crowded | -1.239 | 1.630 | -4.175 | 1.986 | 0.039 | 0.031 | 1733.541 | 1568.763 | 1.002 |
| direct | direct_ci_lower | direct_ci_upper | direct_pvalue | indirect | indirect_ci_lower | indirect_ci_upper | indirect_pvalue | total | total_ci_lower | total_ci_upper | total_pvalue | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| variable | ||||||||||||
| poverty | -0.587495 | -1.434112 | 0.322005 | 0.18250 | 1.309085 | -0.072178 | 2.836966 | 0.06875 | 0.721591 | -0.338839 | 2.086792 | 0.20625 |
| rev_rating | 0.633379 | -0.829189 | 2.157524 | 0.37875 | -1.289166 | -3.720816 | 1.015514 | 0.24875 | -0.655786 | -3.149393 | 1.663989 | 0.56625 |
| num_spots | 0.028533 | -0.033383 | 0.090457 | 0.37000 | 0.217850 | 0.080762 | 0.413679 | 0.00000 | 0.246383 | 0.113811 | 0.454804 | 0.00000 |
| crowded | -1.093956 | -3.234903 | 0.999069 | 0.31875 | -1.955351 | -6.184027 | 1.820493 | 0.32375 | -3.049307 | -7.292861 | 0.265982 | 0.07125 |
az.plot_forest(sdm.inference_data)
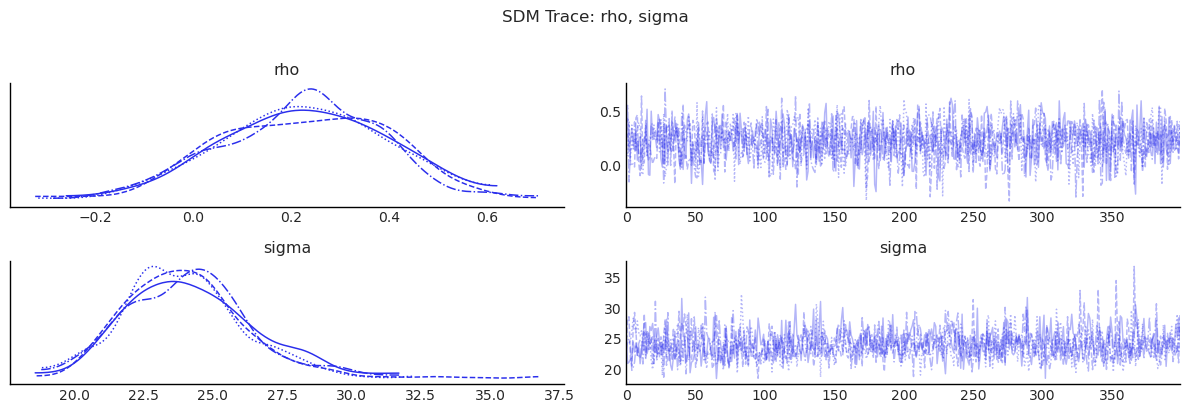
display(diagnostics_table(sdm.inference_data, ["rho", "beta", "sigma"]))
show_trace(sdm.inference_data, ["rho", "sigma"], "SDM Trace: rho, sigma")
| mean | sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|
| rho | 0.223 | 0.171 | 1721.619 | 1299.748 | 1.000 |
| beta[Intercept] | 87.065 | 78.479 | 1647.108 | 1361.040 | 0.999 |
| beta[poverty] | -0.643 | 0.469 | 1777.358 | 1611.313 | 1.000 |
| beta[rev_rating] | 0.688 | 0.770 | 1474.167 | 1515.338 | 1.000 |
| beta[num_spots] | 0.019 | 0.031 | 1849.856 | 1659.838 | 1.000 |
| beta[crowded] | -0.998 | 1.134 | 1640.344 | 1335.392 | 1.003 |
| beta[W*poverty] | 1.173 | 0.632 | 1609.890 | 1571.707 | 1.000 |
| beta[W*rev_rating] | -1.168 | 0.976 | 1791.192 | 1595.063 | 1.000 |
| beta[W*num_spots] | 0.162 | 0.052 | 1706.260 | 1534.498 | 0.999 |
| beta[W*crowded] | -1.239 | 1.630 | 1733.541 | 1568.763 | 1.002 |
| sigma | 24.095 | 2.253 | 1229.013 | 1530.625 | 1.001 |
/tmp/ipykernel_7302/3581438262.py:11: UserWarning: The figure layout has changed to tight
plt.tight_layout()

5) SDEM: SLX + Spatial Error¶
Model:
Interpretation:
Neighbor covariates matter directly (through \(WX\)),
and unmodeled shocks are spatially correlated (through \(u\)).
sdem, summary_sdem, effects_sdem = fit_and_report(
SDEM,
formula="price_pp ~ poverty + rev_rating + num_spots + crowded",
data=gdf,
W=W,
)
display(summary_sdem)
display(effects_sdem)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| lam | 0.332 | 0.189 | -0.015 | 0.690 | 0.005 | 0.004 | 1539.489 | 1235.231 | 1.004 |
| sigma | 24.203 | 2.263 | 19.927 | 28.106 | 0.069 | 0.055 | 1080.165 | 1484.121 | 1.001 |
| sigma2 | 590.882 | 113.510 | 394.601 | 786.575 | 3.427 | 3.382 | 1080.165 | 1484.121 | 1.001 |
| Intercept | 89.945 | 79.819 | -63.203 | 232.005 | 2.006 | 1.538 | 1581.511 | 1350.080 | 1.001 |
| poverty | -0.559 | 0.437 | -1.390 | 0.225 | 0.011 | 0.008 | 1496.614 | 1618.919 | 1.001 |
| rev_rating | 0.759 | 0.707 | -0.667 | 2.039 | 0.018 | 0.013 | 1559.760 | 1497.604 | 0.998 |
| num_spots | 0.029 | 0.031 | -0.028 | 0.085 | 0.001 | 0.001 | 1543.692 | 1616.363 | 1.000 |
| crowded | -1.035 | 1.123 | -3.371 | 0.899 | 0.030 | 0.021 | 1448.302 | 1425.393 | 1.001 |
| W*poverty | 1.137 | 0.643 | -0.051 | 2.301 | 0.016 | 0.012 | 1641.260 | 1425.588 | 1.000 |
| W*rev_rating | -1.094 | 0.889 | -2.789 | 0.538 | 0.022 | 0.019 | 1612.120 | 1261.345 | 1.007 |
| W*num_spots | 0.180 | 0.052 | 0.080 | 0.276 | 0.001 | 0.001 | 1547.216 | 1573.058 | 1.002 |
| W*crowded | -1.905 | 1.865 | -5.571 | 1.388 | 0.047 | 0.036 | 1585.542 | 1518.769 | 1.002 |
| direct | direct_ci_lower | direct_ci_upper | direct_pvalue | indirect | indirect_ci_lower | indirect_ci_upper | indirect_pvalue | total | total_ci_lower | total_ci_upper | total_pvalue | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| variable | ||||||||||||
| poverty | -0.559307 | -1.359910 | 0.352059 | 0.19375 | 1.136730 | -0.065842 | 2.368550 | 0.07125 | 0.577423 | -0.510218 | 1.674258 | 0.27625 |
| rev_rating | 0.758896 | -0.683113 | 2.140402 | 0.29125 | -1.094126 | -2.845109 | 0.614190 | 0.21125 | -0.335230 | -1.955952 | 1.324704 | 0.69000 |
| num_spots | 0.028610 | -0.031165 | 0.088752 | 0.34500 | 0.179509 | 0.079824 | 0.281964 | 0.00250 | 0.208119 | 0.119295 | 0.296502 | 0.00125 |
| crowded | -1.034612 | -3.345251 | 1.112038 | 0.34000 | -1.904590 | -5.525525 | 1.838374 | 0.29375 | -2.939202 | -6.408021 | 0.446602 | 0.08750 |
az.plot_forest(sdem.inference_data)
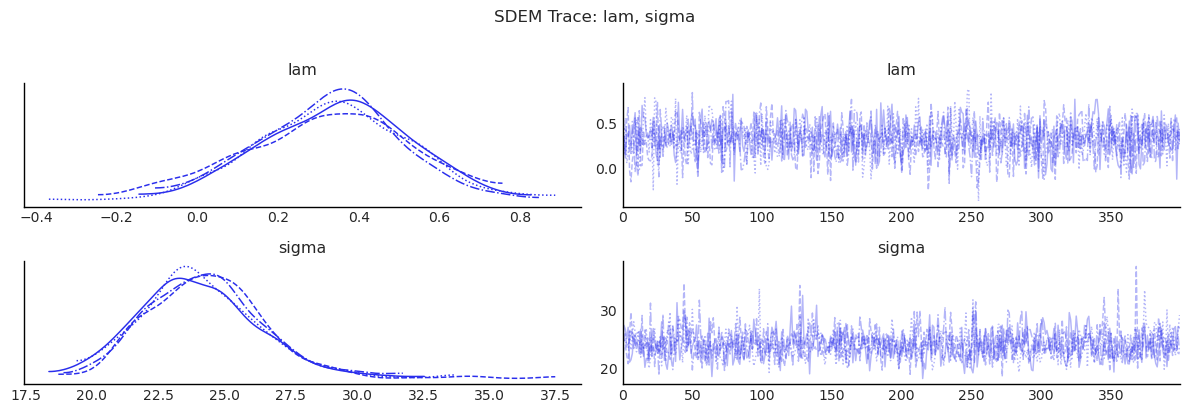
display(diagnostics_table(sdem.inference_data, ["lam", "beta", "sigma"]))
show_trace(sdem.inference_data, ["lam", "sigma"], "SDEM Trace: lam, sigma")
| mean | sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|
| lam | 0.332 | 0.189 | 1539.489 | 1235.231 | 1.004 |
| beta[Intercept] | 89.945 | 79.819 | 1581.511 | 1350.080 | 1.001 |
| beta[poverty] | -0.559 | 0.437 | 1496.614 | 1618.919 | 1.001 |
| beta[rev_rating] | 0.759 | 0.707 | 1559.760 | 1497.604 | 0.998 |
| beta[num_spots] | 0.029 | 0.031 | 1543.692 | 1616.363 | 1.000 |
| beta[crowded] | -1.035 | 1.123 | 1448.302 | 1425.393 | 1.001 |
| beta[W*poverty] | 1.137 | 0.643 | 1641.260 | 1425.588 | 1.000 |
| beta[W*rev_rating] | -1.094 | 0.889 | 1612.120 | 1261.345 | 1.007 |
| beta[W*num_spots] | 0.180 | 0.052 | 1547.216 | 1573.058 | 1.002 |
| beta[W*crowded] | -1.905 | 1.865 | 1585.542 | 1518.769 | 1.002 |
| sigma | 24.203 | 2.263 | 1080.165 | 1484.121 | 1.001 |
/tmp/ipykernel_7302/3581438262.py:11: UserWarning: The figure layout has changed to tight
plt.tight_layout()

MCMC Sampling Adequacy¶
Bayesian estimation of spatial models has a well-known efficiency
pitfall: the spatial dependence parameter \(\rho\) (or \(\lambda\)) often
mixes slowly, so a chain that looks converged in its point estimate
can still produce posterior credible intervals that are 10–12 % too
narrow because the sampler has not visited the tails enough times
[Wolf et al., 2018]. The
spatial_mcmc_diagnostic helper checks effective sample size, sampler
yield, \(\hat{R}\), and HPDI stability for the spatial parameter and
warns when any threshold is violated.
from bayespecon import spatial_mcmc_diagnostic
# Run on the SDM (most parameters; both rho and impact summaries depend on it)
report = spatial_mcmc_diagnostic(sdm, emit_warnings=False)
report.to_frame()
| ess_bulk | ess_tail | r_hat | mcse_mean | yield_pct | hpdi_drift_pct | adequate | |
|---|---|---|---|---|---|---|---|
| parameter | |||||||
| rho | 1721.618976 | 1299.74764 | 1.000308 | 0.004137 | 107.601186 | 0.075601 | True |
sdm.spatial_diagnostics()
| statistic | median | df | p_value | ci_lower | ci_upper | |
|---|---|---|---|---|---|---|
| test | ||||||
| LM-Error-SDM | 191.332401 | 7.245911 | 1 | 0.000000 | 0.005830 | 1825.679074 |
| Robust-LM-Error-SDM | 4.573298 | 4.368310 | 1 | 0.032474 | 0.067665 | 10.705100 |
ols.spatial_diagnostics()
| statistic | median | df | p_value | ci_lower | ci_upper | |
|---|---|---|---|---|---|---|
| test | ||||||
| LM-Lag | 19.509247 | 9.684711 | 1 | 0.000010 | 0.043135 | 86.951604 |
| LM-Error | 3.323993 | 2.651153 | 1 | 0.068276 | 0.539922 | 10.604467 |
| LM-SDM-Joint | 3480.693794 | 1446.506357 | 5 | 0.000000 | 18.560596 | 17819.396000 |
| LM-SLX-Error-Joint | 3478.462840 | 1445.223432 | 5 | 0.000000 | 18.526830 | 17793.840557 |
| Robust-LM-Lag | 11.405358 | 10.850537 | 1 | 0.000732 | 5.083639 | 20.802546 |
| Robust-LM-Error | 6.024115 | 5.731068 | 1 | 0.014112 | 2.685091 | 10.987549 |
sar.spatial_diagnostics_decision()

sem.spatial_diagnostics()
| statistic | median | df | p_value | ci_lower | ci_upper | |
|---|---|---|---|---|---|---|
| test | ||||||
| LM-Lag | 172.441267 | 52.788342 | 1 | 0.000000 | 0.108023 | 877.939657 |
| LM-WX | 30267.238036 | 6784.374119 | 4 | 0.000000 | 66.961156 | 142490.364555 |
| Robust-LM-Lag | 7.136585 | 0.888915 | 1 | 0.007553 | 0.003560 | 25.167073 |
| Robust-LM-WX | 4070.414903 | 500.861896 | 4 | 0.000000 | 11.514896 | 14237.164000 |
report
SpatialMCMCReport(parameters=['rho'], ess_bulk={'rho': 1721.618975952847}, ess_tail={'rho': 1299.7476399296434}, r_hat={'rho': 1.0003077944547376}, mcse_mean={'rho': 0.004136803152868457}, nominal_size=1600, yield_pct={'rho': 107.60118599705292}, hpdi_drift_pct={'rho': 0.07560087735308905}, warnings_triggered=[], adequate=True, adequate_by_param={'rho': True})
Model Comparison¶
# Collect all fitted models for comparison
model_dict = {
"OLS": ols,
"SLX": slx,
"SAR": sar,
"SEM": sem,
"SDM": sdm,
"SDEM": sdem,
}
idata_dict = {name: m.inference_data for name, m in model_dict.items()}
Bayes Factor Model Comparison¶
Bayes factors provide an alternative to information criteria for comparing competing models. While WAIC and LOO assess predictive performance, Bayes factors compare marginal likelihoods — the probability of the data under each model, integrated over all parameter values weighted by the prior:
This makes Bayes factors sensitive to the prior: models with diffuse priors on unnecessary parameters are penalized more heavily, because the marginal likelihood averages over all possible parameter values weighted by the prior. In spatial models, this means that models with many WX coefficients under wide priors (e.g., SLX, SDM, SDEM) can receive substantially lower marginal likelihoods than more parsimonious alternatives (e.g., OLS, SAR, SEM) — even if their log-likelihoods are similar.
Interpreting Bayes factors (Kass & Raftery, 1995):
BF range |
Evidence strength |
|---|---|
1 – 3 |
Anecdotal |
3 – 10 |
Moderate |
10 – 30 |
Strong |
30 – 100 |
Very strong |
> 100 |
Extreme |
Method. We use bridge sampling (Meng & Wong, 1996) to estimate each model’s log marginal likelihood, following the R bridgesampling package (Gronau et al., 2020). The implementation uses ESS weighting, two-phase convergence, and MCSE diagnostics. For reliable estimates, 40,000+ posterior samples are recommended.
Important caveat. Bayes factors can be very sensitive to prior specification. Models with diffuse priors on many parameters will tend to have lower marginal likelihoods. This is by design — it is the Bayesian Occam’s razor at work — but it means that Bayes factors and information criteria may disagree when priors are uninformative.
bayes_factor_compare_models(model_dict, method="bridge", log=True).round(3)
/tmp/ipykernel_7302/497883469.py:1: UserWarning: Bridge sampling with 1600 posterior samples for 'OLS' may yield imprecise marginal-likelihood estimates. A conservative rule of thumb is 40,000+ samples (Gronau, Singmann, & Wagenmakers, 2017).
bayes_factor_compare_models(model_dict, method="bridge", log=True).round(3)
| OLS | SLX | SAR | SEM | SDM | SDEM | |
|---|---|---|---|---|---|---|
| OLS | 0.000 | 3.022 | 1.207 | -1.247 | 8.251 | 3.292 |
| SLX | -3.022 | 0.000 | -1.815 | -4.269 | 5.228 | 0.270 |
| SAR | -1.207 | 1.815 | 0.000 | -2.454 | 7.044 | 2.085 |
| SEM | 1.247 | 4.269 | 2.454 | 0.000 | 9.498 | 4.539 |
| SDM | -8.251 | -5.228 | -7.044 | -9.498 | 0.000 | -4.958 |
| SDEM | -3.292 | -0.270 | -2.085 | -4.539 | 4.958 | 0.000 |
bayes_factor_compare_models(model_dict, method="bic", log=True).round(3)
| OLS | SLX | SAR | SEM | SDM | SDEM | |
|---|---|---|---|---|---|---|
| OLS | 0.000 | -1.387 | -2.168 | 0.402 | 0.314 | 0.228 |
| SLX | 1.387 | 0.000 | -0.781 | 1.789 | 1.701 | 1.615 |
| SAR | 2.168 | 0.781 | 0.000 | 2.571 | 2.482 | 2.397 |
| SEM | -0.402 | -1.789 | -2.571 | 0.000 | -0.089 | -0.174 |
| SDM | -0.314 | -1.701 | -2.482 | 0.089 | 0.000 | -0.086 |
| SDEM | -0.228 | -1.615 | -2.397 | 0.174 | 0.086 | 0.000 |
Bridge Sampling vs. BIC¶
BIC: SAR > SLX > OLS > SEM (SAR wins, SLX is moderate, SEM is worst)
Bridge: SAR > SEM > OLS (SAR wins, SEM is moderate)
The two methods can produce qualitatively different model rankings. This is expected and reflects a fundamental difference in what they assume about priors:
BIC approximates \(\log(ML) \approx \hat\ell_{\max} - \frac{k}{2}\log(n)\), which assumes unit-information priors (priors containing as much information as a single observation). The penalty per parameter is fixed at \(\frac{1}{2}\log(n) \approx 2.1\) for \(n = 77\).
Bridge sampling integrates over the actual priors in the model. When priors are wide (e.g.,
Normal(0, 100)on WX coefficients), the marginal likelihood penalizes each such parameter by roughly \(\log(\sigma_{\text{prior}} / \sigma_{\text{post}})\), which can be 5–10× larger than the BIC penalty.
This is why models with many WX terms (SLX, SDM, SDEM) may look reasonable under BIC but receive extreme Bayes factors under bridge sampling: the wide priors on the WX coefficients are “wasted” — they spread probability mass over implausible parameter values, reducing the marginal likelihood. This is Bayesian Occam’s razor at work, and bridge sampling is generally more trustworthy because it accounts for the actual prior specification.
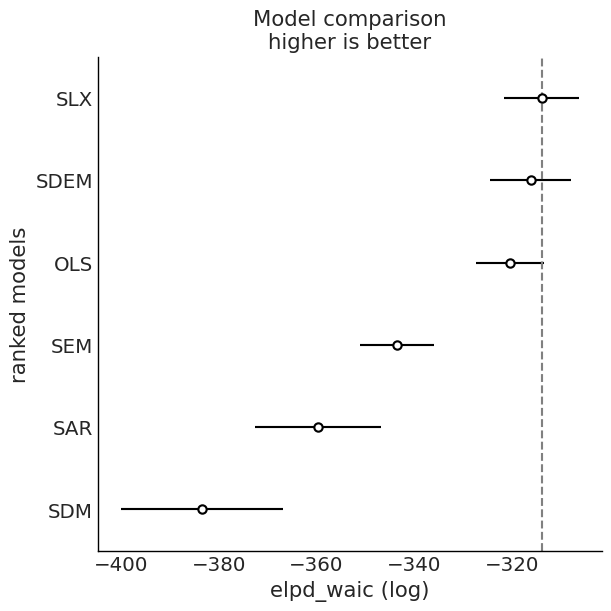
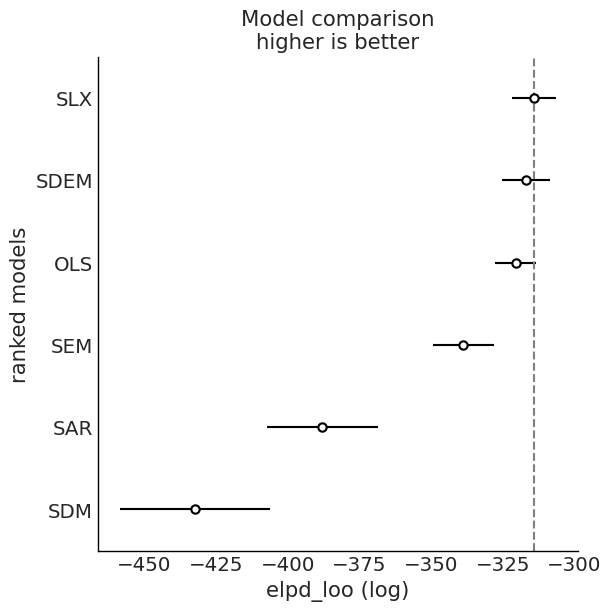
Model Comparison: WAIC and LOO¶
We compare fitted models using information criteria from ArviZ.
# WAIC and LOO comparison
for ic in ("waic", "loo"):
cmp = az.compare(idata_dict, ic=ic)
az.plot_compare(cmp)
/home/runner/micromamba/envs/test/lib/python3.14/site-packages/arviz/stats/stats.py:1652: UserWarning: For one or more samples the posterior variance of the log predictive densities exceeds 0.4. This could be indication of WAIC starting to fail.
See http://arxiv.org/abs/1507.04544 for details
warnings.warn(
/home/runner/micromamba/envs/test/lib/python3.14/site-packages/arviz/stats/stats.py:1652: UserWarning: For one or more samples the posterior variance of the log predictive densities exceeds 0.4. This could be indication of WAIC starting to fail.
See http://arxiv.org/abs/1507.04544 for details
warnings.warn(
/home/runner/micromamba/envs/test/lib/python3.14/site-packages/arviz/stats/stats.py:1652: UserWarning: For one or more samples the posterior variance of the log predictive densities exceeds 0.4. This could be indication of WAIC starting to fail.
See http://arxiv.org/abs/1507.04544 for details
warnings.warn(
/home/runner/micromamba/envs/test/lib/python3.14/site-packages/arviz/stats/stats.py:1652: UserWarning: For one or more samples the posterior variance of the log predictive densities exceeds 0.4. This could be indication of WAIC starting to fail.
See http://arxiv.org/abs/1507.04544 for details
warnings.warn(
/home/runner/micromamba/envs/test/lib/python3.14/site-packages/arviz/stats/stats.py:1652: UserWarning: For one or more samples the posterior variance of the log predictive densities exceeds 0.4. This could be indication of WAIC starting to fail.
See http://arxiv.org/abs/1507.04544 for details
warnings.warn(
/home/runner/micromamba/envs/test/lib/python3.14/site-packages/arviz/stats/stats.py:1652: UserWarning: For one or more samples the posterior variance of the log predictive densities exceeds 0.4. This could be indication of WAIC starting to fail.
See http://arxiv.org/abs/1507.04544 for details
warnings.warn(
/home/runner/micromamba/envs/test/lib/python3.14/site-packages/arviz/stats/stats.py:782: UserWarning: Estimated shape parameter of Pareto distribution is greater than 0.69 for one or more samples. You should consider using a more robust model, this is because importance sampling is less likely to work well if the marginal posterior and LOO posterior are very different. This is more likely to happen with a non-robust model and highly influential observations.
warnings.warn(
/home/runner/micromamba/envs/test/lib/python3.14/site-packages/arviz/stats/stats.py:782: UserWarning: Estimated shape parameter of Pareto distribution is greater than 0.69 for one or more samples. You should consider using a more robust model, this is because importance sampling is less likely to work well if the marginal posterior and LOO posterior are very different. This is more likely to happen with a non-robust model and highly influential observations.
warnings.warn(
/home/runner/micromamba/envs/test/lib/python3.14/site-packages/arviz/stats/stats.py:782: UserWarning: Estimated shape parameter of Pareto distribution is greater than 0.69 for one or more samples. You should consider using a more robust model, this is because importance sampling is less likely to work well if the marginal posterior and LOO posterior are very different. This is more likely to happen with a non-robust model and highly influential observations.
warnings.warn(
/home/runner/micromamba/envs/test/lib/python3.14/site-packages/arviz/stats/stats.py:782: UserWarning: Estimated shape parameter of Pareto distribution is greater than 0.69 for one or more samples. You should consider using a more robust model, this is because importance sampling is less likely to work well if the marginal posterior and LOO posterior are very different. This is more likely to happen with a non-robust model and highly influential observations.
warnings.warn(
/home/runner/micromamba/envs/test/lib/python3.14/site-packages/arviz/stats/stats.py:782: UserWarning: Estimated shape parameter of Pareto distribution is greater than 0.69 for one or more samples. You should consider using a more robust model, this is because importance sampling is less likely to work well if the marginal posterior and LOO posterior are very different. This is more likely to happen with a non-robust model and highly influential observations.
warnings.warn(
Bayesian LM Specification Tests¶
The bayespecon.diagnostics module provides Bayesian Lagrange-multiplier tests that operate on posterior draws rather than point estimates. These replace the frequentist LM tests that were previously available.
Below we run the Bayesian LM tests from the fitted OLS model:
bayesian_lm_lag_test— tests \(H_0: \rho = 0\) (no spatial lag)bayesian_lm_error_test— tests \(H_0: \lambda = 0\) (no spatial error)bayesian_lm_wx_test— tests \(H_0: \gamma = 0\) (no WX, from SAR null)bayesian_lm_sdm_joint_test— joint test for SDM (\(H_0: \rho = 0\) and \(\gamma = 0\))bayesian_lm_slx_error_joint_test— joint test for SDEM (\(H_0: \lambda = 0\) and \(\gamma = 0\))bayesian_robust_lm_lag_test/bayesian_robust_lm_error_test— Anselin–Florax robust pair (SAR vs SEM)bayesian_robust_lm_lag_sdm_test/bayesian_robust_lm_wx_test/bayesian_robust_lm_error_sdem_test— Neyman-orthogonal robust testsbayesian_lm_error_sdm_test/bayesian_lm_lag_sdem_test— SDM/SDEM-aware tests using correctly filtered residuals
In practice, prefer the method API: model.spatial_diagnostics() runs the tests wired to that model class, and model.spatial_diagnostics_decision() returns a recommended specification.
Each returns a BayesianLMTestResult with posterior summary statistics and a Bayesian p-value.
# `spatial_diagnostics()` runs all tests wired to a model class
# and returns a tidy DataFrame.
ols.spatial_diagnostics()
| statistic | median | df | p_value | ci_lower | ci_upper | |
|---|---|---|---|---|---|---|
| test | ||||||
| LM-Lag | 19.509247 | 9.684711 | 1 | 0.000010 | 0.043135 | 86.951604 |
| LM-Error | 3.323993 | 2.651153 | 1 | 0.068276 | 0.539922 | 10.604467 |
| LM-SDM-Joint | 3480.693794 | 1446.506357 | 5 | 0.000000 | 18.560596 | 17819.396000 |
| LM-SLX-Error-Joint | 3478.462840 | 1445.223432 | 5 | 0.000000 | 18.526830 | 17793.840557 |
| Robust-LM-Lag | 11.405358 | 10.850537 | 1 | 0.000732 | 5.083639 | 20.802546 |
| Robust-LM-Error | 6.024115 | 5.731068 | 1 | 0.014112 | 2.685091 | 10.987549 |
Compare Spatial Parameters Across Models¶
This cell compares posterior means/intervals for the spatial scalar where present:
rhoin SAR/SDMlamin SEM/SDEM
# Compare spatial parameters across models
spatial_rows = []
for name, model, var in [
("SAR", sar, "rho"),
("SEM", sem, "lam"),
("SDM", sdm, "rho"),
("SDEM", sdem, "lam"),
]:
if var in model.inference_data.posterior:
summary = az.summary(model.inference_data, var_names=[var], round_to=3)
summary.insert(0, "model", name)
spatial_rows.append(summary)
pd.concat(spatial_rows)
| model | mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|---|
| rho | SAR | 0.421 | 0.145 | 0.146 | 0.678 | 0.004 | 0.004 | 1590.247 | 1184.079 | 1.000 |
| lam | SEM | 0.490 | 0.184 | 0.133 | 0.805 | 0.005 | 0.005 | 1508.653 | 918.977 | 1.002 |
| rho | SDM | 0.223 | 0.171 | -0.107 | 0.519 | 0.004 | 0.004 | 1721.619 | 1299.748 | 1.000 |
| lam | SDEM | 0.332 | 0.189 | -0.015 | 0.690 | 0.005 | 0.004 | 1539.489 | 1235.231 | 1.004 |
Matrix-Mode API Example (Optional)¶
The package also supports direct matrix inputs. This is useful if your design matrix is already engineered.
y = gdf[ycol]
X = gdf[xcols]
sar_matrix = SAR(y=y, X=X, W=W)
sar_matrix.fit(draws=200, tune=200, chains=2, random_seed=7, progressbar=False)
display(sar_matrix.summary(round_to=3))
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| rho | 0.410 | 0.149 | 0.119 | 0.662 | 0.008 | 0.008 | 397.492 | 307.574 | 1.004 |
| sigma | 25.221 | 2.285 | 21.377 | 29.617 | 0.131 | 0.100 | 312.948 | 273.619 | 1.000 |
| sigma2 | 641.307 | 118.830 | 456.986 | 877.186 | 6.835 | 5.971 | 312.948 | 273.619 | 0.999 |
| poverty | 0.059 | 0.325 | -0.586 | 0.616 | 0.017 | 0.012 | 391.599 | 355.560 | 0.999 |
| rev_rating | 0.472 | 0.127 | 0.254 | 0.735 | 0.007 | 0.006 | 346.824 | 235.725 | 1.001 |
| num_spots | 0.081 | 0.026 | 0.033 | 0.127 | 0.001 | 0.001 | 307.173 | 285.373 | 1.001 |
| crowded | -1.692 | 0.899 | -3.215 | -0.019 | 0.043 | 0.032 | 421.722 | 407.213 | 0.998 |