Urban Analysis & Spatial Science
Theory, Methods, & Code for Studying Neighborhoods, Cities, & Regions

This text provides an introduction to the technical and theoretical foundations of urban analysis, a field with a long history and surging growth across multiple disciplines. It covers intermediate quantitative methods in urban and regional research via the Python programming language. The book is structured as a series of computational notebooks and serves as both a topical and technical reference manual. Each chapter introduces a topic and its motivation in the social science and public policy literature, moving from basic geoprocessing and spatial analysis into accessibility, segregation, neighborhood change, spatial econometrics, and more. The chapter then carries out an empirical analysis using classic and emerging techniques (occasionally both), walking through the construction and analysis in depth. The goal is to provide a concise coding example demonstrating a real-world application, while contextualizing the analysis with citations and background literature that readers may explore for more depth.
Introduction
![]()
This text provides an introduction to the foundations of modern urban analysis with PySAL, geosnap, and the pydata stack. This collection is suitable for applied researchers or graduate students in the urban social sciences looking to increase their technical capacity in urban data science, as well as students from engineering, computer science, and statistics looking for an introduction to the theoretical foundations of urban analytics. The book’s intellectual tradition extends from the classic Readings in Urban Analysis (Lake, 1983), with extensions to current and emerging theories and methods from across the disciplines of urban social science.
In particular, we emphasize the use of formal, spatially-explicit methods and computational statistics for solving classic problems in the urban domain. What distinguishes this volume from similar alternatives like Geographic Data Science with Python (Rey et al., 2023) and Automating GIS Processes with Python is its focus on the application of advanced spatial analysis techniques to a wide variety of urban research questions. Whereas those texts focus on the integration of geospatial thinking into data science, we focus on the application of spatial data science to conduct social scientific research. This approach focuses less on data structures an algorithms and more on the theoretical nexus between research design and spatially-explicit urban scholarship.
By taking readers through the classic theories of urban analysis before presenting applied examples, this volume provides a pathway for constructing thoughtful models using either structural or experimentalist frameworks that are often required for rigorous policy analysis (Gelman et al., 2020; Heckman, 2005, 2008; Heckman & Vytlacil, 2007; Holmes & Sieg, 2015). These formal models help analysts think through causal relationships in complex systems, and they contrast from the prediction-centric modeling frameworks that are the focus of most data science tutorials (although the approaches are not mutually exclusive). Note, this is not a book focused on causal inference or structural estimation1, but rather on the technical skills in spatial analysis and theoretical foundations in urban topics necessary for analysts to build their own models.
As Alves (2022) describes, machine learning models have been both widely adopted and widely abused in recent years, and academia is no exception. As a result, a great deal of research–especially that using georeferenced data–tends to provide dubious evidence for policy recommendations, relying on support from models which were not designed to answer policy questions. Our goal in this volume is not to critique this work; indeed ML and data science have critical roles in spatial analysis and discovery, and we will discuss important frameworks in later chapters. But our central focus on the nexus between urban theory and spatial methods is designed to foster a tighter integration between rigorous methods for policy analysis, and the special considerations necessary to understand spatial data (Anselin, 1989). As such, the content of this volume is, by design, highly interdisciplinary. Although the book is not explicitly billed as a regional science text, our approach extends from the view that urban and regional analysis should be multidisciplinary, applied to contemporary issues in the social sciences, with a critical nexus to policy and practice.
Applied regional science should be problem-driven, not method-driven or theory-driven. It must be more than the storehouse of analytical methods that have been regional science’s main contribution to date… A modest, but very important, initial step is research that gets beyond the formal aspects of the analytical methods to gain a better understanding of their power and limitations within the contexts, purposes, and processes in which they are used (Isserman 1984). Such research should focus “not just on the models and methods per se, but also on their interpretation, use, and abuse in practice” (Anselin 1991a).
— Isserman (1995)
To that end, we aim to match the “intellectual core” of urban and spatial science as an interdiscipline, following Isserman’s tenets:
- Theory dealing with industrial location, migration, spatial competition, regional growth and development, regional differentiation and hierarchies, and spatial interaction,
- Methods for regional analysis, including economic and demographic models, spatial statistics, and optimization methods
- Policy areas with a spatial dimension, including economic development, environment, housing, labor markets, social service location, and transportation.
These principles that guide our research bear a strong resemblance to the characterization of analytical sociology advanced by Sampson (2002), who describes “Chicago School” inquiry as
- a relentless focus on context (especially place)
- a focus on properties of communities and cities as social systems
- a relational concern with variability in forms of social organization as opposed to population attributes (or composition)
- continual attention to neighborhood change and spatial dynamics (time and space)
- an eclectic style of data collection that relies on multiple methods but that always connects to some form of observation
- a concern for public affairs and the improvement of community life
- an integrating theme of theoretically interpretive empirical research
Although these perspectives focus on different systems (i.e. spatial markets versus social relationships) and different notions of scale (places versus individuals), both perspectives maintain an emphasis on formal structural analysis of hierarchically-networked systems embedded in space (Sampson, 2011). This is an important parallel because analytical urban sociology and regional science very obviously share common DNA. Indeed, the intellectual tradition and analysis of spatial structure articulated famously by Alonso, Muth, and Mills borrows as much from Park and Burgess as it does from Christaller and Von Thunen (Alonso, 1964b). Despite this similarity, overlap between sociology and regional science has waned over time rather than waxed, and it’s rare for Sampson or Park citations to appear in the Annals of Regional Science, just as it is quite rare to find an Isserman or Tiebout citation in the Annual Review of Sociology.
These links are not unknown, but have been celebrated by regional scientists for decades (Quigley, 2001; Schaefer et al., 2011). Indeed, Sampson won the Alonso Memorial Prize in 2013, and Alonso himself credits Burgess as offering the “clearest statement” of the historical theory of spatial structure (Alonso, 1964b). Although Isard (2001) observed that “the three largest subgroups of regional scientists come from geography, planning, and economics,” he also worked hard to place sociology professors on the Regional Science faculty at Penn, and to organize sessions “on regional analysis at conferences of the American Economic Association, Association of American Geographers, American Sociological Association, American Political Science Association, and others.”. The intentional reach into sociology and political science also helps ratify the call by Bailly & Coffey (2005) to better incorporate the human dimension into urban and spatial science.
Under this rubric, doing sound urban analysis requires a strong foundation not only in the technical methods and different modeling strategies, but also a deep understanding of the ways that markets, social groups, public policies, and political economies intersect and interact with space in complex ways 2. Sometimes we forget that economic geography is rooted in behavioral science… Economic geography grows from human ecology, which grows from psychology (Ullman, 1941; Zipf, 1949).
Since the classic Readings in Urban Analysis, few volumes have attempted to provide such a broad coverage of theoretical perspectives in urban analysis. None have provided both theory and code. Here we emphasize that urban analysis sits at the intersection of spatial analysis and social science (Rey & Franklin, 2022). While regional science has historically been criticized for its obsession with methods and its tenuous relationship with practical utility (as described by Isserman above), analytical sociology has also been criticized for treating research methods in policy analysis without appropriate econometric rigor (Harding et al., 2021; Ludwig et al., 2008; Sampson, 2008). Clearly, then, the synergy of these perspectives has much to offer toward a more holistic analysis of urban systems. Quigley (2001) reiterated the linkages across disciplines and the centrality of regional science more than two decades ago
“During the past decade several of the most exciting intellectual challenges in social science have emerged and been framed in exactly the terms familiar to students of regional science. These specific scientific problems have important policy implications, and they are also central to theoretical inquiry in several core disciplines of economics, political science, sociology, and statistics, for example. It is my contention that, at no time since Von Thunen, have spatial relationships been so important in the social sciences and in the policy implications of social scientific inquiry.”
Despite the centrality of this work in modern social science and policy analysis, developing this interdisciplinary perspective on urban spaces requires traversal of many distinct literatures to acquire the breadth of theoretical and methodological tools. This can lead to an inadequate use of “Big Theory” in the age of Big Data (Franklin, 2023b). The goal of this volume is to help consolidate some of this diverse knowledge into a practical text that offers “a rigorous but nontechnical treatment” of major topics in urban analysis and spatial science (Brueckner, 2011) with examples in Python.
Finally, even when some of the best research weds concepts from across the urban disciplines, the work often happens using point-and-click software creating research pipelines that are more prone to human error and cannot be reproduced. It also tends to make strong assumptions about the form and nature of spatial interaction (i.e. how spatial relationships are included in the model) which are important to scrutinize, test, and extend (Aaronson et al., 2021; Ellen et al., 2013; Harding et al., 2009; Hartley, 2014; Schwartz et al., 2021). We prefer to stand on the shoulders of these giants and build upon their work, rather than reimplement and start from scratch. Toward those goals, this book provides background theory on urban systems, drawn from regional science, urban economics, geography, urban planning, and sociology, and demonstrates how to carry out common research tasks in urban social science using free and open source tooling.
By making these tools and their historical development more accessible, we hope to provide some scaffolding toward bridging the gap between theory and practice, with the goal of making cities better for everyone. In our view, this should be the goal of the discipline, as Batty (2019) describes
…There is a bigger role in thinking about a theory of the urban – we have called it city science – that embraces the new data and provides a clear testbed for applications to problems relating to the big questions of our time, inequality, aging, the future of work and so on, all of which have enormous spatial as well as temporal variations that need to be understood and explained. And last but not least, urban analytics should deal with Environment and Planning, the main title of this journal still, for therein lies the motivations for developing these ideas in the first place, so we can provide more sustainable and liveable cities than anything we have achieved or even attempted so far.
Whence Urban Analysis
There are lots of good, open courses, syllabi, and books related to urban data science (or similar nomenclature) today and many of them are written by my close colleagues. All of those materials are good. Still, I think this book fills a particular void that reflects my own view on urban social science. Having trained with sociologists, economists, geographers, and planners, I think there is a clear need for a book that weds today’s computational analytical toolkit with an interdisciplinary perspective on urban studies. In its best form, that’s what regional science is supposed to be (Alonso, 1971; Isard, 1975) :
- more theory than geography
- more space than economics or sociology
- more computation than urban planning or policy
Maybe that categorization will raise eyebrows from my colleagues in each of those respective disciplines, but I’m more than prepared to defend this hill. Perhaps it’s a contrarian position, but there is an important lesson from the long arc of history in quantitative spatial analysis that is underappreciated today 3. Thirty years ago, Berry (1995) in (direct response to (Isserman, 1993, 1995), but indirect) response to widespread hand wringing about the future of the discipline, wrote about his dissatisfaction with regional science, and the way it had drifted from a group of highly motivated scholars breaking new ground in spatial analysis to a “a hardcore group of technocrats who subscribed to Lord Kelvin’s dictum that if it could not be done mathematically it was not worth doing.” By that time, regional science had developed an external stigma that most of its practitioners were doing little more than playing with numbers and mapping the results, without producing any value for understanding how cities work. That perception had merit.
But fifteen years ago, Berry et al. (2008) 4 wrote about the endless promise of the newly emerging “Geospatial Science… a spatially integrated social–environmental science that is transcending older disciplinary attachments, boundaries, and constraints”. In their view, the combination of GIS and more powerful spatial statistical modeling techniques amounted to a fundamentally new science–“geospatial” this time, not “regional”. But they questioned “whether the result [would] be a new discipline or an integrative interdisciplinary pursuit that fosters the broader development of spatially integrated human-environmental inquiry.” The answer was neither.
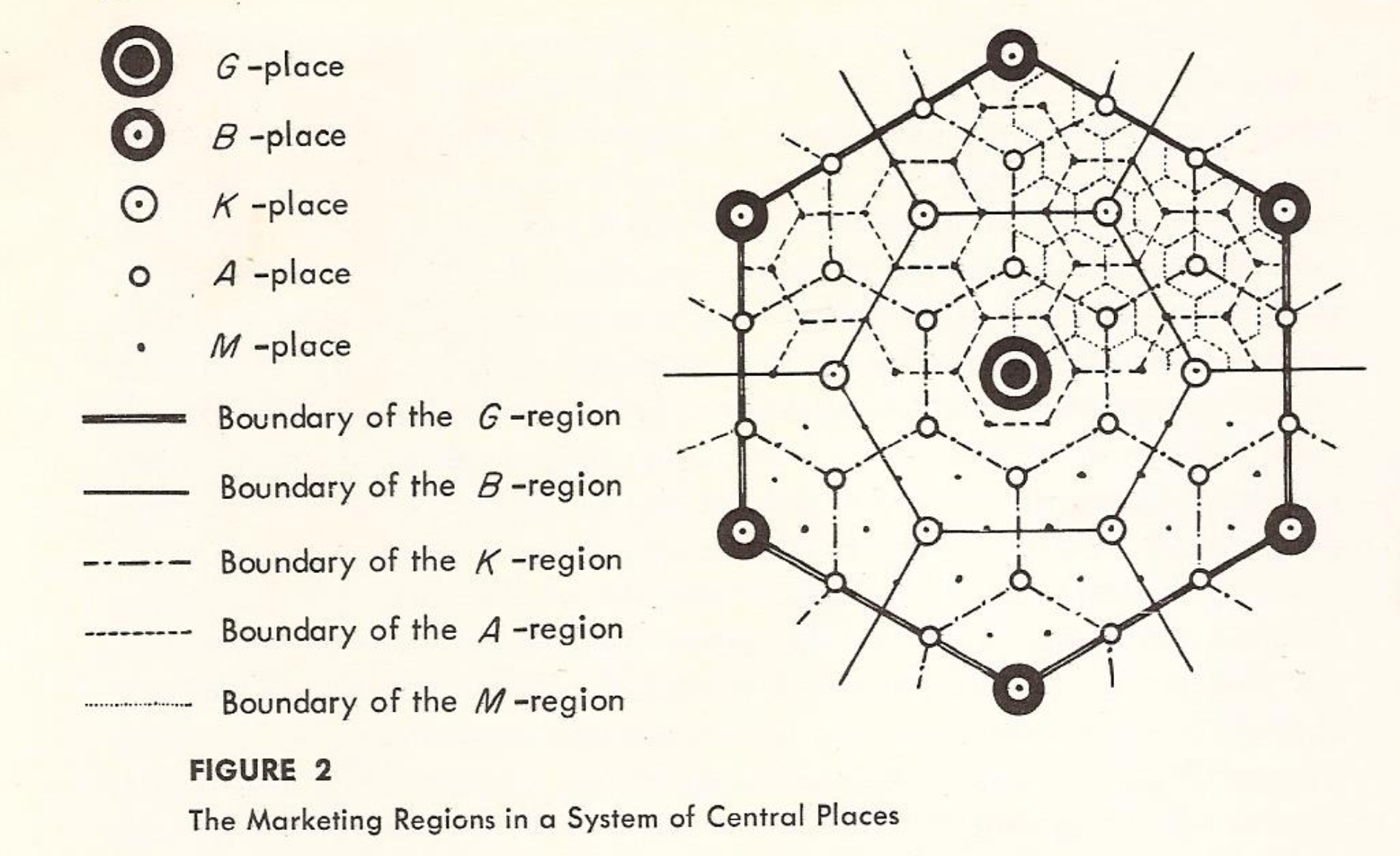
While GIS has made simple mapping and geo-data processing more accessible in a wider variety of fields, the tighter integration between geography and computer science has weakened tethers to the social sciences, and pushed spatial analysis further into the technocratic bubble Berry so loathed. Lots of ‘urban computing’ labs, are packed with computer scientists clamoring to offer opinions about urban analytics; none of them are trained to understand cities5. Thus we end up with fancy hexagonal gridding systems, like Uber’s H3, without even a nod to Christaller (1937), Lösch (1940), Central Places, or Market Areas.


Global Grids, Now and Then

Hexagonal Systems, Now and Then
Today, many scholars of my era are making bold claims about the fundamentally transformative power of spatial data science (another new “science”), “GeoAI”, and “Digital Twins”, that will revolutionize the planet–despite clear calls from leaders in the discipline to please incorporate some social theory (Franklin, 2023b)–and as though we do not have half a century of experience in these topics (Harris, 1985, 1994; Lee, 1973; Spiekermann & Wegener, 2018). While we have some nice modern methods to use and more computational power today, not many seem to realize that we’ve been here (a few times) before. Whither regional science indeed (Berry, 1995). That history (and a longer one I could eat much more space with) leads me to an admittedly very opinionated take on spatial analysis in the social sciences.
The future offers exciting opportunities, but it requires crucial decisions, personal commitments, and pioneering initiatives if
regional science[urban data science?] is to be lively and healthy for another 40 years.– Isserman (1993)
Don’t be dissuaded from continuing past the introduction if things sound cynical at first; I’ll only spend the intro editorializing. One goal with this book is to demonstrate my own commitment to the health and longevity of spatial science, but doing do requires taking an honest and critical view, both past and present, of the [broadly defined] discipline in which I myself participate. Three decades ago, regional scientists worried what the future might look like once the discipline’s founding Ph.D department closed. Today, my inner Isserman can’t help but worry what has been lost (and will continue to be) now that former flagship institutions believe the entire (still growing) domain can be re-labeled and repackaged into a one-year graduate program. Without real departments or core texts, it’s hard to build institutional memory but easy to remake past mistakes.
Demarcating Urban Analysis and Spatial Science
Like its predecessor, urban analysis is lost in space. The field continues to re-brand and segment itself, and while there is strength in numbers, there is weakness in diffusion (Franklin, 2023a). With few exceptions, RSUE is the domain of economists, EPB is the domain of geographers, and Urban Studies is the domain of sociologists (Getis, 2007). We don’t even engage with Urban Affairs. What maintains through the division is the strength of spatial analytical approaches, and the scholars who know their topical domains well enough to extract meaning from the application of these methods.
Toward that end, spatial analysis and urban analysis are not synonymous. Spatial analysis is a tool in the urban analytical toolkit (Páez & Scott, 2004). Urban analysis (and regional/spatial science), in my view, is the application of quantitative methods to the study of neighborhoods, cities, and regions; the goal of urban analysis is to understand (at least a piece of) how these places are shaped by histories, markets, social processes, and political economies that operate within and around them.
“Older regional scientists may recall that in 1953-1954, the designation spatial science (Alonso’s Raumforschung) was considered the most appropriate.”
– Isard (2001)
That has always been the goal of regional science (Isard, 1956, 1960), though, I prefer Alonso’s original term “spatial science,” first because I do not have a preferred scale (region vs neighborhood), and second because spatial econometrics provide the discipline’s most foundational tool (Anselin, 2007; Henderson, 2007; Quigley, 2007). ‘Urban analytics’, then (the plural noun), is akin to Raudenbush & Sampson (1999)’s “ecometrics”, or the broader field of psychometrics from which it’s inspired: a measurement science devoted to developing theoretically-informed, policy relevant scales, indicators, or variables that can be used to understand cities and formally evaluate policy measures (Irwing, 2018; Larimian & Sadeghi, 2021; Roberts, 1979). Although articulated differently, Wolf (2023) makes a similar case for city science.
Many methods and models widely used in the spatial sciences have been originally worked out in quantitatively more advanced social and economic science disciplines such as psychometrics, sociometrics and econometrics. Under certain circumstances, however, specific problems can arise, especially when such methods and models have not been sufficiently adapted to the specific needs of the spatial sciences. One well known problem of this kind is the spatial dependence among spatial data which often requires developing a specific spatial methodology.
– Fischer & Nijkamp (1985)
Together then, urban analytics provide a set of metrics for interpreting places, and spatial science provides a set of formal theoretical and modeling frameworks for studying their effects. This is a social science view of the world, not a data science one. Data science is deeply useful for our goal of understanding cities, but its role is instrumental. I think that is a clear distinction between the material in this book and the way other similar volumes are presented.
The rush to colonize spatial data science (as opposed to regional science) means that few students learning ‘urban analytics’ have any training in location theory, which limits dramatically their ability to apply and interpret spatial analyses (Alonso, 1964a; Isard, 1949). It also leads to confusion about which analytical strategies are appropriate in different research contexts and how to formalize space for understanding different questions. At worst, this risks training a generation of scholars brimming with fancy technical abilities but little domain knowledge–which is exactly the disastrous recipe of which regional science critics were afraid.
Thus, we know why retail establishments outbid residential dwellings for land near employment centers (Alonso, 1964a), why most transportation trips are a short distance (Hansen, 1959; Zipf, 1949), why race matters for understanding the spatial economy (Glaeser et al., 2004; Kain, 1968; Schelling, 1971) and why some people can opt into quality school systems supported by a strong municipal tax base (Tiebout, 1956), while others remain stuck in place (Sharkey, 2013). Further, we know that people, firms, and places interact with one another in space (Anselin, 1988; Cliff & Ord, 1969) rendering many traditional quantitative methods unusable for statistical inference. Those lasting insights should be the foundation that urban analysis builds upon.6 With due respect to Batty (2022) (another hero of mine), this is a different endeavor from the architect’s quest to define ‘the city’. In architecture and urban design it may be true that
“Throughout history, cities had been considered first and foremost as physical forms whose functioning might be improved by physical planning. It took the rest of the last century to transform this notion of planning into the social rather than the physical organisation and even now, there is much left to do to enable this transformation and to integrate both perspectives.”
But in urban social science, that notion is absurd (Ullman, 1941). By the time city planning was devised in the early 20th century, the theoretical foundations of regional science were already 100 years old (von Thünen, 1826). Following, in urban economics, ‘the city’ has a clear, if imperfect definition based on the demand for land: ‘the city’ is any place that the residential rent gradient exceeds the agricultural rent gradient (because that demand is what leads to development and density)7 8. And while that definition is simplistic and sometimes contested (even egregious on occasion), it provides a formal, quantifiable definition rooted in behavioral theory.
In this sense, cities have been viewed by social scientists first as social constructs since at least Von Thunen’s time–more than a century prior to Mumford’s–where the physical layout of urban form follows as a consequence of social interaction (e.g., transporting goods to the marketplace). The Weber brothers preceded Mumford by a generation (Weber, 1929; Weber, 2005), and their work was first and foremost about the interrelationships between social structure and individual behaviors, not the physical form of streets and buildings. Further, by the time Mumford penned The City in History, The Chicago School sociologists were also decades into their research program and their own (social) definition of The City, with Park et al. (1925) already more than 40 years old, and Wirth (1938) having already published a succinct definition.9
Following, there is a distinct difference in the study of ‘spatial bundles’ (Arribas-Bel & Fleischmann, 2023) versus the study of processes that give rise to them, and interrogating why particular kinds of spatial bundles occur. The proverbial Geographer to which Arribas-Bel & Fleischmann (2023) appeal sounds identical to the Little Prince’s Geographer from which Berry (1995) desperately wanted to differentiate; it is for the Geographers, in their view, to define ‘bundles’ using their computers and algorithms, while the Explorers are left to interrogate what the bundles mean, and why they are there. While Dani and Martin are two of my closest colleagues and collaborators, I would argue city science requires a perspective different from bundles10 and a coalition far broader than Geography (and if you can’t argue with your friends, who can you argue with?). We can’t understand cities without the tradition of Zorbaugh & Chudacoff (1983), McFadden (1978), or Ellen (2023).
In a similar vein, urban science is not environmental science (Haining, 2003). A common difficulty in teaching spatial analysis is attempting to cater to too many audiences . But while I have taken an ambitious swing with this book, the goal is to speak to a unified set of social scientists who share common theories and models of human behavior. This distinction is important because the kinds of data we use (i.e. vector vs raster) and the kinds of models we build (i.e. discrete choice vs kriging) are designed for fundamentally different systems (Anselin, 2002). Hurricanes, icebergs, and mineral deposits are all strongly influenced by space, but do not make utility-maximizing decisions, mimic each other, or develop rational expectations.
I think this is a longstanding but ill-addressed distinction between geographers and economists in regional science, and is partly responsible for the factioning among “spatial data scientists;” while I think environmental science is a complementary discipline, I disagree with the idea of an integrated “social-environmental” science described by Berry et al. (2008)— and what’s more, that concept was already 30 years old (Isard, 1972)… As Isserman (1996) liked to say: “it’s obvious, it’s wrong, and anyway, they said it years ago.”
Now, having spent the last several paragraphs lauding the importance of economic formalization, I’d be remiss if I didn’t point out that everyone agrees economists are the worst11. If there is a discipline that believes the entire domain of urban studies is theirs by exclusive right, it’s economics. They believe that about every domain. And that same haughty, exclusionary attitude and dogmatic adherence to formalization (at the cost of ridiculous abstraction) is why there are no more Regional Science departments. The world decided it was not useful to prove that demand curves are downward sloping and that land prices fall with distance to amenities.
So to be clear, urban science is not urban economics. Urban economists, including some of the best econometricians on the planet, are still publishing papers that don’t account for spatial dependence of any kind (Aaronson et al., 2021; Quast et al., 2017; Voith et al., 2022) (no, clustering your standard error or including a unit fixed effect–or both–won’t save you (Anselin & Arribas-Bel, 2013; Wolf et al., 2021)). Elsewhere, they disagree with the notion of spatial spillovers specified by theory (Gibbons & Overman, 2012), but vehemently defend models built atop a house of cards. Today’s ‘quantitative spatial model’ (Redding, 2023; Redding & Rossi-Hansberg, 2017) doesn’t depend on the classic ‘featureless plain,’ but it assumes the modern equivalent. We need a broader coalition than Econ as well.
To this day, many economists are unaware that for an OLS model to be properly specified, residuals must be spatially independent in the mapped region of study.
Again, part of the problem is nobody bothers to publish in the other fields’ journals. So while the economists will surely tell me how wrong I am about everything in this book, at least it will have baited them into the conversation. (If you can’t tell I’m joking, this is all intended as good fun. Cities are great, but this material can be dense, so let’s enjoy a few laughs when we can). I think The Wizard of Oz metaphor works on aggregate but perhaps falls apart when trying to assign labels. Sociology is probably the least cowardly of the social sciences.

But now that everyone has been insulted, I can reiterate that my point is: we’re all studying cities together and each discipline brings a necessary but insufficient set of strengths to the table. Let’s work together and do Urban Science again :). I will do my best to cover what each of these fields has taught me about the most important ways to conduct urban scholarship, but by definition that means I can’t do any single perspective justice.
Although all regional scientists study socio-economic aspects of earth regions, we approach it in many different ways.
– Getis (2007)
Adopting a few central tenets from each of these fields provides a framework for the approach to urban scholarship described in this book:
- Neighborhoods, cities, and regions are constructed, inhabited, and governed by people, which makes urban studies a fundamentally social science (Park et al., 1925).
- People are quasi-rational utility-maximizers. This is not the strict homo-economicus rationality of Adam Smith where people ignore sunk costs and are perfectly self-interested. Rather it means people behave by making a series of interdependent choices, each of which is defined by (error-prone) utility maximization (Manski & McFadden, 1981; McFadden, 1976; McFadden & Train, 2000). Every person’s utility function can be different and people will often disagree strongly. For a devout religious person, abstinence from drugs and alcohol may be the ‘rational’ decision because it fulfills their ideological goals. For a person struggling with addiction, using drugs may be the ‘rational’ decision at any point because the immediate benefit of drug use outweighs the delayed potential health consequences (these can be the same person!). This means even though people have unique preferences and distinct utility functions, they behave according to the same framework (Ben-Akiva et al., 1997).
- People interact with one another, which means choices are interdependent. Greater levels of empathy may mean that other people’s happiness can play a large role in my own utility function (i.e. this allows people to be self-interested by caring for others)(Brown, 2014). This also means that everyone’s utility function is dynamic and context-dependent.
- Part of a utility function is based on how other people behave and how they perceive me; if everyone is facing the wrong way in the elevator, I may follow suit because the other people may know more than I do, and I don’t want to look foolish–so my utility function is based on my perception about how I am being perceived (Asch, 1951). This also leads to rational expectations because my utility function can be based on how I believe others will behave (or how they will perceive me) in the future.
- Each of these dynamics happens at multiple scales, meaning cities, nations, corporations, etc. all behave in similar ways with similar dynamic consequences (Brueckner, 1998, 2003; Brueckner & Lee, 1989; Heikkila, 1996). The urban system contains many actors at several hierarchical scales (and different levels of power/authority).
- Distance is an important component of social interaction (Anselin, 2002; Tobler, 1970). For example, I am more likely to feel peer pressure to keep my lawn tidy if my next-door neighbor has short grass than if my neighbor down the block has short grass (Sampson et al., 1999); distance can be ‘social’, (e.g. how similar I think I am to someone else), geo-physical (e.g. how proximate I am to another person on the earth), or transactional (e.g. how often I exchange goods with a particular vendor).
- Even though the behavior of each individual can be explained and well-understood as governed by a simple model, the interaction between people can lead to chaos, complexity, emergence, and deeply unpredictable behavior in the system as a whole (Batty, 2005; Schelling, 1971, 1972, 1978).13
- Land markets are a central unifying feature of many underlying dynamics described above (Alonso, 1964a); land markets define where things are located, and traveling to access things (whatever they are) takes time, and time is ultimately valuable to everyone. Sometimes land markets even define access to things in a discrete fashion (e.g. tax rates defined by residence in a particular state or school attendance defined by residence within a boundary polygon.)
In my opinion, these are a summary of the basic assumptions of integrated land-use/transportation modeling (Anas, 1984; Anas & Kim, 1996; Wegener, 1994, 2004, 2021), and also the behavioral foundations of the game-theoretic view of urban planning espoused by the “Illinois School” (Hopkins, 2001; Hopkins & Knaap, 2019).14
Perspective
It is worth pointing out that, like Isserman (1995), I have a distinctly American perspective on urban studies. While I am confident the methods and lessons in this book are transferrable anywhere on the globe, I am trained to understand cities through the specific history of institutionalized racism that has shaped housing, land-use, transportation, education, and other urban policy decisions both explicitly and implicitly since the country’s founding. In the U.S., neighborhood scholarship and the understanding of social inequality is inextricably linked to housing policy and racial segregation (Charles, 2003; Galster, 1988; Galster & Keeney, 1988). The sociospatial structure of American cities is not a random spatial process, but an expression of racialized public policy decisions that persist today (Kain, 1968; Kain, 1992; Sampson, 2013; Wilson, 1987, 1996). Galster & Killen (1995)‘s famous “geography of opportunity” is a reference to the American irony that the fabled and oft marketed ’land of opportunity’ is not, in fact, equally accessible, or distributed randomly in space. Instead, ‘opportunity’ seems to follow a remarkably stable spatial structure maintained by urban policy measures.
Here, space and land policy have been used by both private and public institutions as instruments for hoarding privilege, requiring decades of legal action to help ensure adequate protection under the law. The Fair Housing Act is an explicit recognition that housing is a major driver of social inequality (and that it requires legal protection to ensure equal access to opportunity), and there is an important legal tradition the U.S., (led by the NAACP and the ACLU) of challenging government policies under the equal protection clause. These court cases have resulted in some of the most important and well-known housing demonstration projects ever carried out, like the Gautreaux program in Chicago (Keels et al., 2005; Mendenhall et al., 2006; Rosenbaum & Deluca, 2008), and the five city Moving to Opportunity (MTO) project (Dawkins et al., 2015; Feins & Shroder, 2005; Leventhal & Brooks-Gunn, 2003; Ludwig et al., 2013), and made clear that policy decisions, like the siting of public housing were (and are) at least partly responsible for the demarcating the geography for opportunity and determining who has access to it.
I was lucky study the MTO microdata early in my graduate career (Pendall et al., 2015), and the methodological framework I developed (Knaap, 2017) and applied in my dissertation is the core of the federal evaluation of the Baltimore Housing Mobility Program that resulted from the Thompson v. HUD decision. Some of my favorite scholars like Stefanie DeLuca and Camille Zubrinsky Charles testified15 in the Thompson trial, subjecting analyses to a level of scientific rigor that must literally withstand cross-examination in a federal courtroom16. That strict scrutiny is partly why there has always been a careful emphasis on methods, causality, and interpretation in the MTO literature specifically, and the neighborhood effects literature more generally (Clampet‐Lundquist & Massey, 2008; Harding et al., 2021; Ludwig et al., 2008; Manski, 1993). In these cases, “the algorithm fits the data” does not suffice.
“A true regional scientist is concerned with acquiring knowledge. First, he wants to satisfy his curiosity and eagerness to understand phenomena; second, he wants to attack social problems. Hence, although he may want to study the city and region abstractly and as an intellectual pursuit, he should also seek to attain knowledge that leads to wiser policies helping to mitigate urban and regional problems. It necessarily follows that before a scholar or practitioner can do anything about a pressing social problem, he should know at least something about his subject matter.”
– Isard (1975)
Familiarity with this history and experience developing methods for evaluating Fair Housing programs gives me a particular view on the use and abuse of urban analytics, and the relationship between theory, methods, and policy. Toward that end, while there are good books on urban economics (Arnott & McMillen, 2006; Brueckner, 2011; Mills & Hamilton, 1994), housing policy (Clark, 2021; Green & Malpezzi, 2003; Myers, 1990), segregation (Musterd, 2020; Schelling, 1978), analytical sociology (Hedström, 2011) spatial analysis (Rey et al., 2023), spatial statistics (Rogerson, 2021) regional science (Henderson & Thisse, 2008) economic geography (Muller et al., 1998) or Python programming (Downey, 2016) there are none that try to weave these themes together. I’m going to give that a shot here. The style I’m shooting for is Think Stats (Downey, 2014) meets Lectures in Urban Economics17 (Brueckner, 2011), which means technical but accessible, and expressed using more computation and demonstration than math (though equations are presented frequently to help formalize and define each model and its assumptions).
The goal of this volume is to promote open urban science, and the content is structured as a series of computational notebooks. The concept behind this style of presentation is that it exposes the full “life cycle” of a research project on each topic. You may disagree with my perspective, but in each chapter I lay out the logic and application of a particular method of urban analysis that is both canon, and has been applied in my own work. This situates the analysis in the context of a particular theory or policy domain, but exposes the entire computational pipeline, so that if you find my assumptions or my theoretical framing contentious, you can easily translate the method into your preferred application—as long as you show all the breadcrumbs, as I have :). If you think I got something fundamentally wrong, I also welcome discussion and Pull Requests. In both science and public policy, we often shoot for consensus through debate, and exposing all the ugly bits for scrutiny is the point of open science18 (Rey, 2009, 2017; Wolf, 2023).
Data, Measurements, and Models
Many constructs in urban social science are unobservable. The amount of ‘utility’ each family receives from the home it occupies, the extent of the ‘neighborhood’ each child traverses, the level of ‘accessibility’ each worker enjoys, the amount of ‘segregation’ experienced by each ethnic group, and the level of ‘spatial spillover’ attributable to some public policy are all unobservable quantities that are immeasurable directly. But all of them are critical to understand how cities, neighborhoods and regions affect the lives of their residents. Sometimes these concepts themselves stem from unobservable social processes like ‘gentrification’, ‘disorder’, ‘opportunity’, or ‘collective efficacy’, all of which require a set of assumptions and models to approximate.
In that sense, the notion of “the neighborhood” or “the city” is both very real and present, but also abstract and intangible. There is a strong parallel between notions of place in spatial science and the concept of self in social psychology (Goffman, 1959; Mead, 1934); both take on multiple meanings dependent on context, both can be “measured” in many ways, both are shaped and defined by external and internal perceptions, and the way one is defined at any given point has direct and indirect influences on the way it functions. “The self” is distinct from a person (with a passport) just as “the neighborhood/city” is distinct from administrative zone (with a taxation boundary). For that reason, urban analytics has much to gain from psychometrics because both fields depend on a critical feedback between theory and measurement (and psychometricians have been working on these problems for far longer).
Many measurable variables in urban spaces (neighborhood composition, access to the urban core, etc.) can be conceived as partial outcomes from an underlying (latent) social process, and the goal is often to understand the social processes rather than the measurable indicators (Knaap, 2017; Raudenbush & Sampson, 1999; Van Acker et al., 2010). This is a “model-based” view of the world, where we propose a conceptual model (of data or process) and test whether the empirical data fit that model (Anselin, 1988). This is distinct from a “data-based” view of the world prominent in data science where the model is based on pure fit; the difference is akin to the distinction between factor analysis and principal component analysis, in which the former is a model of a latent variable and the latter is a model of data. Revelle (n.d.) is a master of describing this style of quantitative research.
“Throughout the book we will propose models of the data and try to evaluate those models in terms of how well they fit. Conceptually, we use the equations
\[ Data = Model + Residual \]
to represent the problem of inference. We evaluate how well our models fit by examining Residual as defined as
\[ Residual = Data − Model \]
and evaluate the magnitude of some function of the residual (Judd and McClelland, 1989). These equations would seem to imply a greater quantitative level of measurement precision than is generally the case, and should be treated as abstractions to remind us that we are evaluating models of data and need to continuously ask how appropriate is the model. The distinction between model and residual is not new, for it dates at least to Plato. As discussed by Stigler (1999) the whole of nineteenth century statistical theory was based upon this distinction between physical truth as modeled by Newton and actual observations taken to extend the theories. In statistical analysis, residual is typically treated as error, but by treating our data in terms of what we know (model) and what we don’t know (residual) we recognize that better models can explain some of the residual as well.”
— Revelle (n.d.)
Some argue this is the difference between a social scientist’s view of the world and a statistician’s view of the world, but the methodological philosophy matters less. The important point is that we are often more interested in the data-generating process (DGP) than the actual data themselves, and the focus on process means we often make assumptions based on theory or assert testable hypotheses about how the process works. This is like when Stefan Wagner (p. 71) says
Note that, in the social sciences, it is quite common to write down linear relations of the form (9.2) that are intended to describe the structure of a system, but are not to be taken as a short-hand for linear regression. On the other hand, this is largely the opposite of standard practice in applied statistics where, when someone writes (9.2), they often don’t mean anything else than that they intend to run a linear regression of \(Y_i\) on \(W_i\).
When possible in this book, we take the “social sciences approach”, where we generally consider a process (and maybe write down an equation) that we believe governs the DGP, then ask either in combination or sequence
- what is the best way to estimate the parameters of interest? (implicitly acknowledging that the conceptual/structural equation is not necessarily the estimating equation)
- are there other DGPs that could generate similar patterns but where the parameters would be mistakenly identified using a particular estimating equation?
- do the empirical data fit this model? (i.e. should our conceptual model should be rejected by the data?)
I like to think this is also akin to Alonso’s belief the “importance of theories of facts as well as theories of explanation” (Isserman et al., 2001, p. 294). It also embodies Isard’s concept of regional science inquiry:
In contrast with geography, anthropology, and political science, regional science, much like economics and to a lesser extent sociology, finds a basic thread in a methodology which: (1) embraces the construction of theoretical models of various degrees of abstraction, based upon intuitive hypotheses, or hypotheses suggested by the previous accumulation and processing of empirical materials; and (2) the testing of these models against statistically valid materials, the refinement and reformulation of the models in the light of the results, and, in non-ending succession the retesting and restructuring of the models.
– Isard, according to Isserman (1993), p.4
Keeping this mindset, I think it is deeply important to think about what we measure and why. Any time you write about quantitative analysis, it is also a good idea to check with Gelman.
My hypothesis on all this is that when students are taught research methods, they’re taught about statistical analysis and a bit about random sampling. Then when they do research, they’re super-aware of statistical issues such as how to calculate a standard error and also aware of issues regarding sampling, experimentation, and random assignment—but they don’t usually think of measurement as a statistical/methods/research challenge. They just take some measurement and run with it, without reflecting on whether it makes sense, let alone studying its properties of reliability and validity. Then if they get statistical significance, they think they’ve made a discovery, and that’s a win, so game over.
Cities are full of really noisy measurements and systematically non-random error, and if we do not consider that error (or its sources) carefully, models with urban data will lead to nonsense.
Outline
This book has grown from the collection of tutorials, teaching materials, and other research bits I have developed over the last six years (and some portions are adapted and expanded from these materials). There is also a great deal of new empirical material that has not been discussed elsewhere. The first few sections (one and three, in particular) provide a review of basic geoprocessing and spatial analysis that should be familiar from other materials (but this volume would be incomplete without a basic coverage).
The following chapters present topics that I have not seen covered in similar spatial analysis materials, or perhaps not covered in the style that I would deliver them, including things like spatial interpolation, accessibility, segregation, and factor ecology. The final three sections present more advanced topics that are typically introduced only in advanced methods courses in certain disciplines, including spatial dynamics, spatial econometrics, and location choice modeling. While these sections provide only a brief introduction to these topics, many students in urban studies are never exposed to these methods unless they participate in specific subdisciplines like transportation modeling or advanced econometrics.
The collection of resources for Python-centric spatial analysis is growing rapidly. This book covers intermediate material and presumes basic knowledge of both Python and geoprocessing, ideally with some knowledge of spatial analysis. A natural sequence for students in urban social science or spatial data science might be something like
- Geocomputation in Python for an introduction to Python and geoprocessing
- Geographic Data Science with Python for an introduction to spatial analysis
- Urban Analysis and Spatial Science (this volume) for coverage of intermediate methods and modern applications in research and practice.
The book is structured as a series of computational notebooks and serves as both a topical and technical reference manual. In each chapter, we introduce a topic and its motivation in the social science literature. We then carry out an analysis using classic and emerging techniques (occasionally both), walking through the construction and analysis in depth. The goal is to provide a concise coding example demonstrating a real-world application, while contextualizing the analysis with citations and background literature that readers may explore for more depth. Each of the topics covered herein could be the focus of its own volume.
Not a single piece of this book has been written with the assistance of an LLM—with the one caveat being the cover image (which is not written!). I use direct quotes the way Nas uses samples; they are woven in frequently, and each is simultaneously an homage to a pioneer that has shaped my perspective, a nod to fellow enlightened, and a signal of disciplinary reverence to appreciative students.19
For the former, see other excellent texts like Cunningham (2018), Huntington-Klein (2022), Angrist & Pischke (2008), Pearl (2000), or Pearl & Mackenzie (2018). For the latter, see Manski & McFadden (1981), Train (2001), Heckman & Urzúa (2010), or Holmes & Sieg (2015). Another great resource is Heckman’s slide deck on econometric policy evaluation↩︎
In truth, this is closer to the urban “meta-discipline” approach of Alonso (1971)↩︎
In particular, I can imagine a cadre of British geographers raising a quarrel over this proposition. In their classic text, Fotheringham et al. (2007) argue that “quantitative geography has recently reached a stage of maturation whereby it is no longer a net importer of ideas and techniques from other disciplines but, rather, it is a net exporter.” But their own evidence to support the notion of geographic theory is a small tweak to McFadden’s discrete choice model. While it is true the competing destinations model is an important contribution to urban studies, it is also true that the model is imported from economics.↩︎
To clarify, I am not picking on Brian Berry. Quite the opposite. Berry’s scholarship is legendary, and his citations will appear dozens of times throughout this book. He was a founding member of the ‘quantitative revolution’ in geography that ultimately birthed regional science. He and his contemporaries at the University of Washington including Waldo Tobler, Richard Morrill and Art Getis who studied under faculty like William Garrison and Edward Ullman (to include only a small handful of the most famous names) are among the most prestigious group in spatial analysis (Morrill, 1983). For that reason, Berry’s opinion (including any cognitive dissonance therein) is a valuable indicator of the field’s status↩︎
Seriously, do not trust a computer scientist’s take on cities. They are dying to opine for some reason, but while they are great at math, they aren’t trained in the structure, function, or politics of urban spaces, and they don’t have a clue what they are talking about. If someone with a Ph.D in physics starts waxing lyrical about urban anything, run the other direction (Hoover, 1963).↩︎
These are not ‘geographical laws’ like fractal scaling or the ubiquitous ‘near things are more alike than distant things’; they are empirically-robust behavioral theories that explain why humans and markets interact in predictable ways through spatial relationships.↩︎
Of course, regional scientists have always famously (and hilariously) failed to actually define the region… (Isserman, 1995). So there’s also that.↩︎
Ok, the bid-rent model isn’t actually any good at predicting the location of Agricultural land anymore (Muth, 1985), so this is really more like ‘any place the residential rent gradient is greater than zero’ (or maybe a another land-consumptive industry like warehousing?) In any case, you can posit a reasonable definition using that framework.↩︎
In fairness, in Suburbia and Beyond, Mumford basically foreshadows all of Bowling Alone (Putnam, 2001)–and our contemporary screen addiction–in his dystopian description of the future ‘burbs. But despite being well-read in economics (particularly German economics!), he didn’t seem to grasp the concept of land markets (or market-based cities, in general), or the ways we could have easily used land-use and transportation policy to avoid the ever-detested sprawl (Alonso, 1964a; Anas & Rhee, 2006). He also appears oddly narrow-minded in his willingness to credit urban scholarship outside his network of architects and designers. In Mumford (1970), he claims “when ‘The Culture of Cities’ appeared a generation ago the literature of cities was still extremely meager… most of the current thinking about cities proceeded without sufficient insight into their nature, their function, their purpose, their historic role, or their potential future,” which just sounds crazy, because in that very volume he cites an impressive array of urban scholars including both Weber brothers and the Human Ecologists. But then again, I’m no great fan of famous ’urbanists’… I’m also inclined to take the contrarian position with Montgomery (1998) that Jane Jacobs was no champion of urban diversity, nor someone that took structural inequality seriously; after reading Montgomery’s critique it’s hard to read her description of the ‘daily ballet’ as anything apart from careful marketing by a privileged NIMBY (with a massive platform) whose goal is to Make Manhattan Great Again. We can all agree Robert Moses was a bad guy, but the Jacobian philosophy of pure local land-use control betrays a belief that land markets (and political markets) never fail (ha!). And if that were true, we would not need the Fair Housing Act… Obviously, this is a classic tension in urban planning.↩︎
Indeed, the most intuitive and well-studied “bundle” in urban studies is the housing unit, and one of the discipline’s most important techniques is developing a structural model to decompose the bundle to better understand the influence of its constituent parts (Rosen, 1974).↩︎
If you’re an economist, I apologize, but we both know you are the worst 😝.↩︎
Like most of Getis’s observations, this is still true.↩︎
Wolfram (2002) may get all the glory, but Gestalt psychology discovered emergence first–and it’s the same thing as complexity science. Don’t @ me 😝↩︎
Despite having all my degrees from the University of Maryland, the Illinois School is inescapably the tradition in which I am trained, having grown up in the hallways of the 1990s UIUC planning department.↩︎
Not to mention my colleague and former committee member Rolf Pendall↩︎
While the Thompson case was not a jury trial, there was cross-examination, and my point here is the science in this arena literally becomes adversarial, with the opposing side trying actively to knock down the other’s evidence and conclusions.↩︎
Ok, that’s a lofty target, to be conservative. Allen and Jan are both geniuses that have a brilliant ability to convey dense information in remarkably clear and concise ways. I’m sure I’ll never pull that off, but it’s a good target to shoot for.↩︎
As a grad student, I learned a lot of Python programming by watching the UDST team (Matt Davis and Fletcher Foti, in particular) build UrbanSim2 (Foti & Waddell, n.d., 2014) in the open, and I was deeply influenced by Fletcher’s take on “exhibitionist source”, which is a philosophy I try to adopt in my own work (and I think we do pretty well over in PySAL also).↩︎
One of Nas’s best skills is actually the ability to sample himself, but alas my body of work is not quite large enough yet. Oh well.↩︎