In the last chapter, several commonly-used model specifications were defined, but the choice among them depends on the research question. Naturally, if spillover effects are of substantive interest, then it is necessary to choose a model that includes (at least) \(\rho WY\) or \(\theta WX\), but beyond that, the choice is more complex. The literature basically offers two different strategies; Anselin & Rey (2014) argue that a “bottom-up” strategy is most effective, where we begin with simple models (e.g., OLS), then conduct spatial diagnostic tests to decide whether more complex specifications are necessary. LeSage (2014) and LeSage & Pace (2014) argue for a “top-down” strategy where we begin with a ‘fully specified’ conceptual model.
LeSage (2014, p. 19) goes so far as to say that “there are only two model specifications worth considering for applied work.” When there are theoretical reasons to consider global spillover processes (such as home prices in a hedonic model), then the SDM model is appropriate. In other cases that consider only local spillover effects, the SDEM specification will provide unbiased estimates of all parameters. Their logic (to always prefer the Durbin specifications) is simple: the inclusion of the \(\theta WX\) term ensures that if there is an exogenous spillover process, then it will be measured accurately with only a small efficiency penalty, but omitting the term would lead to bias. The distinction between the SDM versus the SDEM, however, is largely a theoretical choice for a given research question rather than an empirical matter. As LeSage & Pace (2014, p. 1551) describe:
“Global spillovers arise when changes in a characteristic of one region impact outcomes in more than just immediately neighboring regions. Global impacts fall on neighbors to the neighbors, neighbors to the neighbors to the neighbors, and so on… Local spillovers represent a situation where the impacts fall only on nearby or immediate neighbors, dying out before they impact regions that are neighbors to the neighbors… feedback effects arise in the case of global spillovers, but not in the case of local spillovers.”
It follows “that practitioners cannot simply estimate an SDM and SDEM model and draw meaningful conclusions about the correct model specification from point estimates of \(\rho\) or \(\lambda\)… the SDM specification implies global spatial spillovers, while the SDEM is consistent with local spillovers. These have very different policy implications in applied work” (LeSage, 2014, p. 22), because indirect (and total) effects will be underestimated in the case when SDM model is appropriate but the SDEM model is fit because SDEM does not include feedback effects.1
Different specifications imply different DGPs and reflect what you want to study.
The SAR and SDM models which contain the spatially-lagged dependent variable \(\rho Wy\) specify global spillovers; the SLX, SDM, and SDEM models which contain the \(\theta WX\) term specify local spillovers (SDM specifies both). The difference between global and local spillovers pertains to the ways that effects propagate through the system and the ways that model coefficients may be interpreted (Juhl, 2021); SAR assumes explicit spillover processes, whereas SEM assumes spatially correlated omitted variables. You should have theory guiding which specification you want to use, even though most applied work uses a fit-based model selection approach. As described in preceding sections, the difference between the different types of spillovers is a critical distinction for applied work and policy analysis because we generally need to consider marginal effects, which means computing direct and indirect effects for models including a spatial lag. In the examples below, we examine how to fit and compare diagnostics for these different models using the spreg package (Anselin & Rey, 2014; Rey et al., 2021; Rey & Anselin, 2010).
30.1 Data Preparation
Since we are collecting raw parcel data, we will need to do a bit of cleanup and preparation before beginning model construction. The state of Maryland makes available a great set of parcel-level data called PropertyView, which include point and polygon datasets including attributes from the tax assessor’s’ office (e.g. size and sales price of the property, etc.). They also provide sales listings broken down by quarter or aggregated by year, and this is the dataset we use for the model. We will also attach these parcel points to the attributes of the blockgroup they fall inside.
Code
np.set_printoptions(suppress=True) # prevent scientific formatdatasets = DataStore()balt_acs = get_acs(datasets, county_fips="24510", years=2019)balt_lodes = get_lodes(datasets, county_fips="24510", years=2019)# compute access variablesbalt_net = get_network_from_gdf(balt_acs)balt_lodes["node_ids"] = balt_net.get_node_ids( balt_lodes.centroid.x, balt_lodes.centroid.y)balt_net.set(balt_lodes["node_ids"], balt_lodes["total_employees"].values, name="jobs")access = balt_net.aggregate(2000, name="jobs", decay="exp")# download PropertyView data and read as a geodataframeheaders = {"user-agent": "Wget/1.16 (linux-gnu)"}zfilename ="BACIparcels0225.zip"# download the zip file onto the local diskz = requests.get("https://www.dropbox.com/scl/fi/xub9kdq5eug6pcsiib0bf/BACIparcels0225.zip?rlkey=f5zwjp7uyl7xpzkmep9o92aec&st=9vc03ft5&dl=0", stream=True, headers=headers,)withopen(f"./{zfilename}", "wb") as f: f.write(z.content)gdf = gpd.read_file("./BACIparcels0225.zip", layer="BACIMDPV")gdf = gdf.set_index("ACCTID")zfilename ="Statewide-Res-Sales-CY2018.zip"# get the 2018 Sales data to join to parcel pointsz = requests.get("https://www.dropbox.com/s/sstsedw9bhtlhyw/Statewide-Res-Sales-CY2018.zip", stream=True, headers=headers,)withopen(f"./{zfilename}", "wb") as f: f.write(z.content)sales = gpd.read_file("./Statewide-Res-Sales-CY2018.zip")sales = sales.set_index("acctid")# keep only sales from 2018, drop duplicate geom column# CRS in this file is epsg:26985 (meters)balt_sales = sales.join(gdf.drop(columns=["geometry"]), how="inner")# attach job access databalt_sales["node_ids"] = balt_net.get_node_ids( balt_sales.to_crs(4326).geometry.x, balt_sales.to_crs(4326).geometry.y)balt_sales = balt_sales.merge( access.rename("job_access"), left_on="node_ids", right_index=True)# keep only residential parcelsbalt_sales = balt_sales[balt_sales.RESIDENT ==1]balt_sales = balt_sales[balt_sales.DESCLU =="Residential"]# remove apartment buildingsbalt_sales = balt_sales[balt_sales.RESITYP !="AP"]# drop observations with missing variablesbalt_sales = balt_sales.dropna(subset=["STRUGRAD", "YEARBLT"])# get a month columnbalt_sales["date"] = balt_sales.tradate.astype("datetime64[ns]")balt_sales["month"] = balt_sales.tradate.str[4:6]# convert typebalt_sales["YEARBLT"] = balt_sales["YEARBLT"].astype(int)balt_sales["struc_age"] =2018- balt_sales["YEARBLT"]balt_sales["age_square"] = balt_sales["struc_age"] **2balt_sales.DESCBLDG = balt_sales.DESCBLDG.astype("category")balt_sales["STRUGRAD"] = balt_sales["STRUGRAD"].astype(float)# keep only improved parcels less than $1.5mbalt_sales = balt_sales[balt_sales.considr1 >35000]balt_sales = balt_sales[balt_sales.considr1 <1500000]balt_sales = balt_sales[balt_sales.struc_age >0]balt_sales = balt_sales[(balt_sales["STRUGRAD"] <9) & (balt_sales["STRUGRAD"] >2)]balt_sales = balt_sales[balt_sales["SQFTSTRC"] >300]balt_sales = balt_sales.merge( balt_acs.drop(columns=["geometry"]), left_on="bg2010", right_on="geoid")balt_sales = balt_sales.reset_index(drop=True)
Generating contraction hierarchies with 16 threads.
Setting CH node vector of size 83534
Setting CH edge vector of size 254770
Range graph removed 258484 edges of 509540
. 10% . 20% . 30% . 40% . 50% . 60% . 70% . 80% . 90% . 100%
Removed 6336 rows because they contain missing values
/var/folders/j8/5bgcw6hs7cqcbbz48d6bsftw0000gp/T/ipykernel_88514/4245329051.py:9: UserWarning: Geometry is in a geographic CRS. Results from 'centroid' are likely incorrect. Use 'GeoSeries.to_crs()' to re-project geometries to a projected CRS before this operation.
balt_lodes.centroid.x, balt_lodes.centroid.y
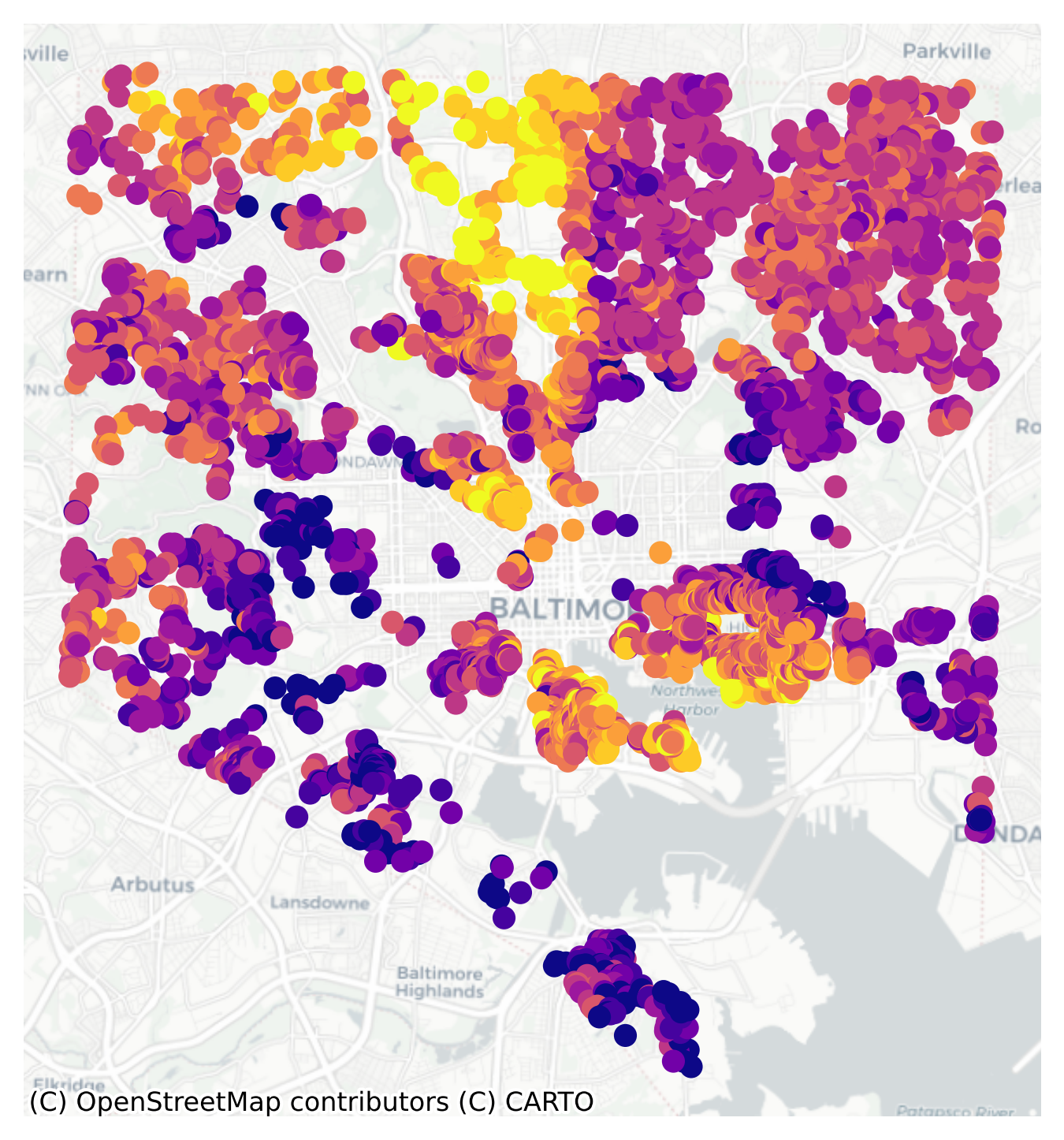
We generally start with ESDA (following the bottom-up strategy) to ensure we even care about spatial econometrics. We begin by mapping the dependent variable (housing price, here) and examining any global and local autocorrelation
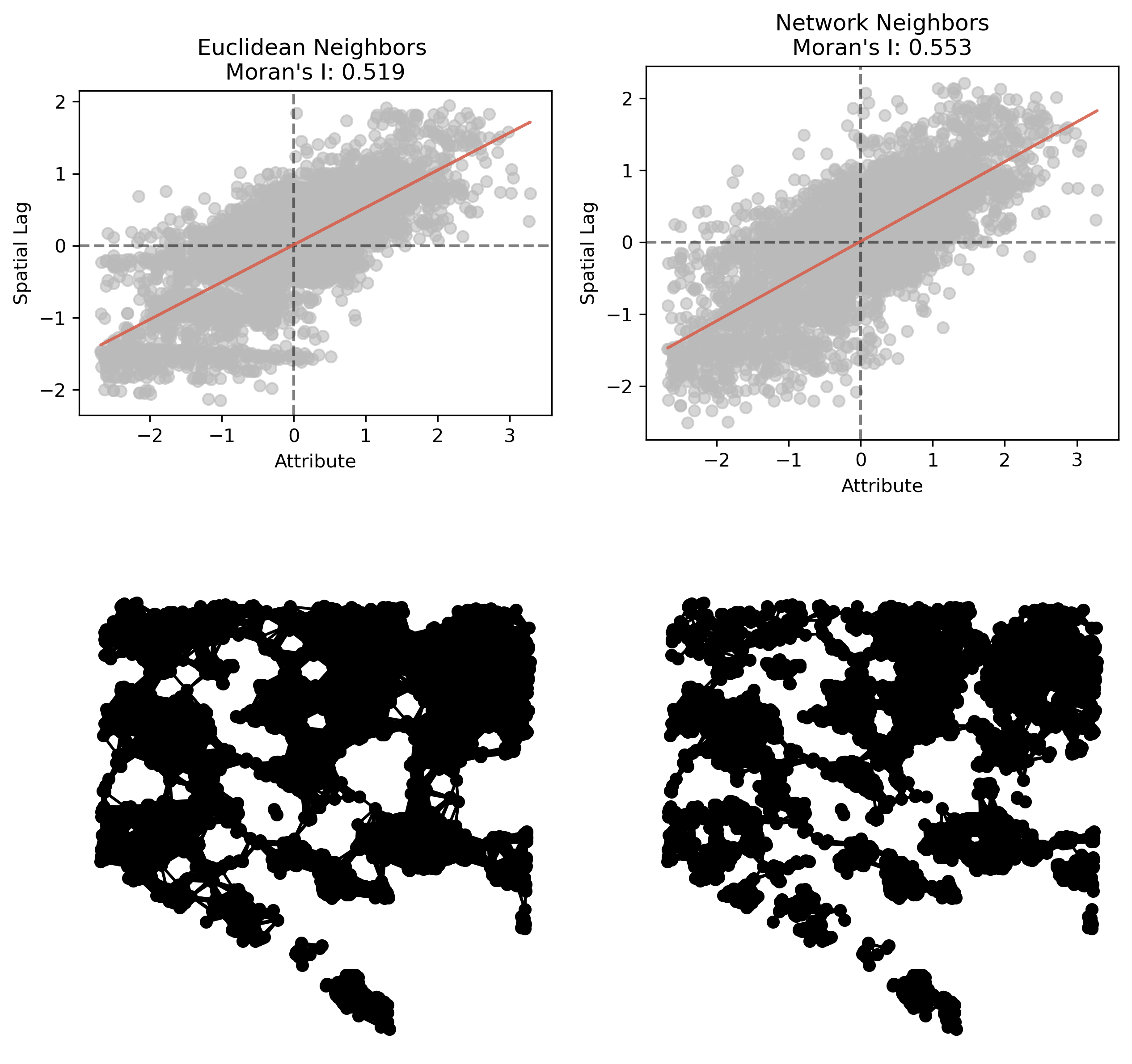
There are definitely spatial patterns, but they’re also not uniform. There’s probably autocorrelation in the sales prices, but it seems to be particularly strong in some pockets. We should be sure to check both global and local statistics. As such, we need a spatial Graph object to define the relationship between housing sales, and we have seen in prior chapters the importance of considering travel network structure. Here we will fit two different graphs and examine global and local autocorrelation using both.
To check global autocorrelation we follow the same basic procedure, creating Moran objects for both types of Graph (to which we refer as \(W\), following the spatial econometric terminology).
For reference, we also plot the spatial structure of each graph below its Moran scatterplot. The comparison shows (as expected) that the network-based neighborhood results in more localized neighbor-sets and higher levels of autocorrelation (.55 versus .52).
30.2.2 Local Stats
And following, we will do the same with LISA plots of the local Moran statistics.
Code
## | fig-cap: LISA of Home Sales Prices in Baltimorelisa = esda.Moran_Local( balt_sales.log_price, w_net, n_jobs=-1,)ax = lisa.plot(balt_sales, alpha=0.7, figsize=(7, 7))ax.axis("off")ctx.add_basemap(ax=ax, source=ctx.providers.CartoDB.Positron, crs=balt_sales.crs)plt.show()
The local Moran shows that our significant Moran statistic is driven by hotspots in “the Wedge” in the north-center of the city and the Inner Harbor, as well as coldspots in East and West Baltimore.
30.3 Models
Taking different modeling strategies, we can vary the way we operationalize \(p(h)\) to best identify the coefficients of interest, including the potential for spatial spillover (e.g. the price of one unit affecting the prices of those nearby). We specify the main parts of this model using Wilkinson formula, which is familiar if you have ever used R (Wilkinson & Rogers, 1973).
Here we will specify the log of sales price as a function of structural characteristics (size, age, dwelling type, construction type, and ‘structure grade’, as well as a squared age term to capture historic effects), demographic and socioeconomic attributes of the home’s census blockgroup, and its accessibility to jobs. A nice thing about Wilkinson formulas in formulaic is the ability to transform variables dynamically, thus here we set several variables as categorical (using the C() convention), and log-transform the square footage of the structure.
We will start by fitting the classic regression model which assumes observations are independent; in this case, that means the sales price of a home is dependent entirely on attributes of that home and is unaffected by homes nearby. We can start by fitting the model using the statsmodels package, which is the standard regression library in Python and provides a nice interface a builtin (classic) diagnostics.
\[y = \beta X + \epsilon\]
30.3.1.1 Using statsmodels
To proceed with statsmodels, we use the ols function from its ‘formula api’ (which is designed to accept Wilkinson formulas). The function returns an OLS class, upon which we call the fit method. Once the model is fit, the summary method returns a table of coefficients and model diagnostics.
Notes: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified. [2] The condition number is large, 6e+05. This might indicate that there are strong multicollinearity or other numerical problems.
For a first shot, this is a decent model, with an \(R^2\) value greater than 0.7. Most of the variables are significant, except for the construction materials, in which only the siding has a significant effect. Otherwise, the coefficients are as expected. Housing prices increase with larger and newer homes (though historic homes also get a bump). Townhomes are less expensive than single family, and there are some small effects from the neighborhood’s demographic composition, the one exception being median income, which is relatively large.
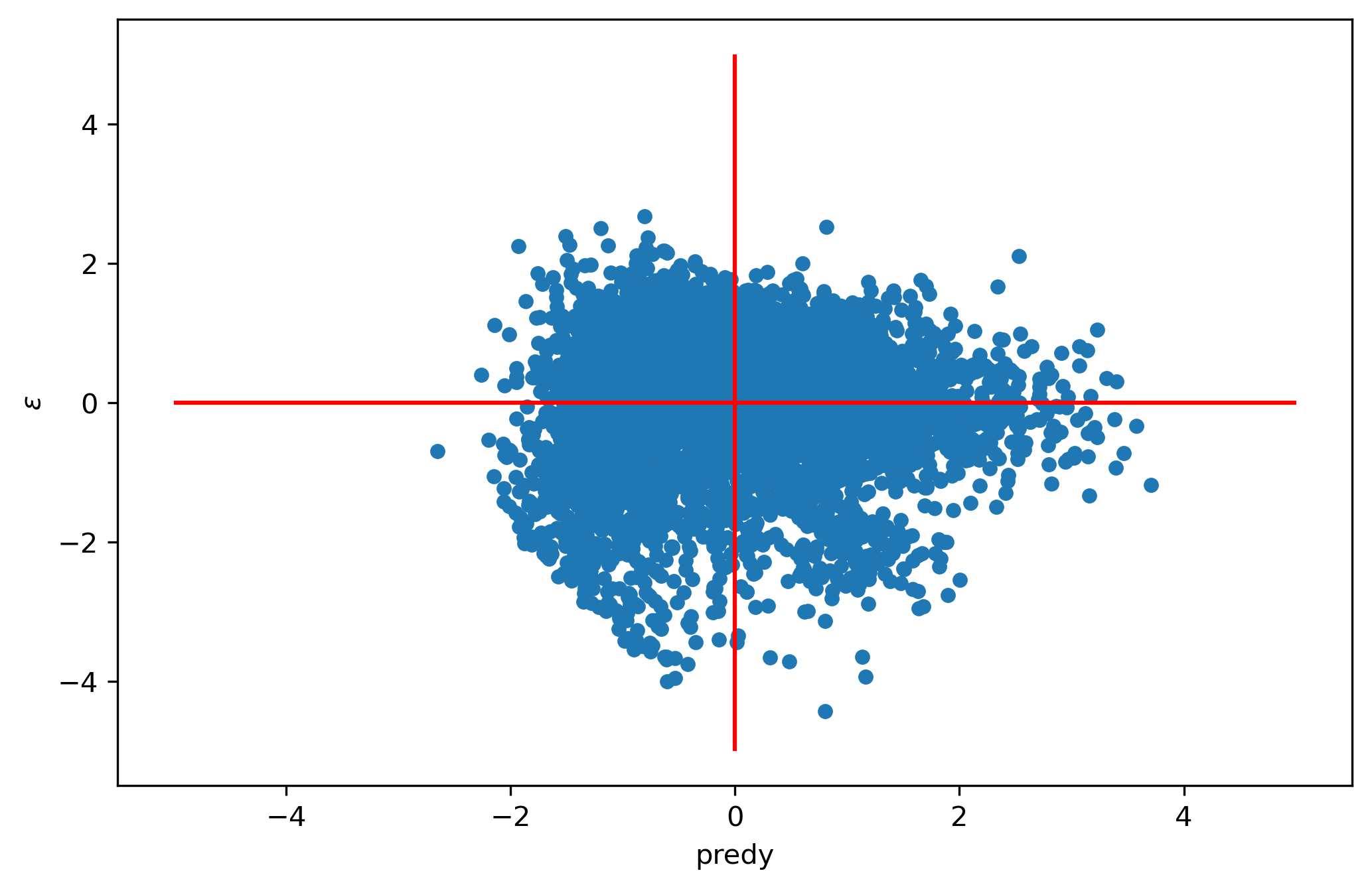
With linear regression models, among our primary concerns are that model residuals are independent and identically-distributed (I.I.D.). They do not necessarily need to be normal (though it’s ideal if they are), but they should be independent from one another (and ideally follow a known probability distribution). If the residuals are not identically-distributed, then robust errors can help insulate inferences, however the independence criterion is more difficult to handle. To check these criteria, it is common to plot the (standardized) predicted values against (standardized) residuals and visually assess randomness.
With this model the residuals are imperfect though not wholly unreasonable.
30.3.1.2 Using spreg
To generate spatial diagnostics for our model, we need to re-fit it using the spreg package from PySAL. However, since spreg does not understand Wilkinson formulas natively, we use the formulaic package, whose Formula class consumes a dataframe and the formula string, then returns the response vector and design matrix as spreg requires them. All other spatial specifications can be performed via options in the spreg estimation classes2.
Code
y, X = Formula(formula).get_model_matrix(pd.DataFrame(balt_sales))
Fitting this model using spreg we pass the y and X variables to the OLS class, but since we also want spatial diagnostics, we also include the Graph object (to the w argument), and include spat_diag=True which computes Lagrange Multiplier tests for spatial dependence in the residual3. Here we also compute the Moran test on the residuals, which requires an extra option given its additional computational overhead.
Once model is estimated using spreg, the coefficients and tests can be viewed
Code
print(model_ols_spreg.summary)
REGRESSION RESULTS
------------------
SUMMARY OF OUTPUT: ORDINARY LEAST SQUARES
-----------------------------------------
Data set : unknown
Weights matrix : unknown
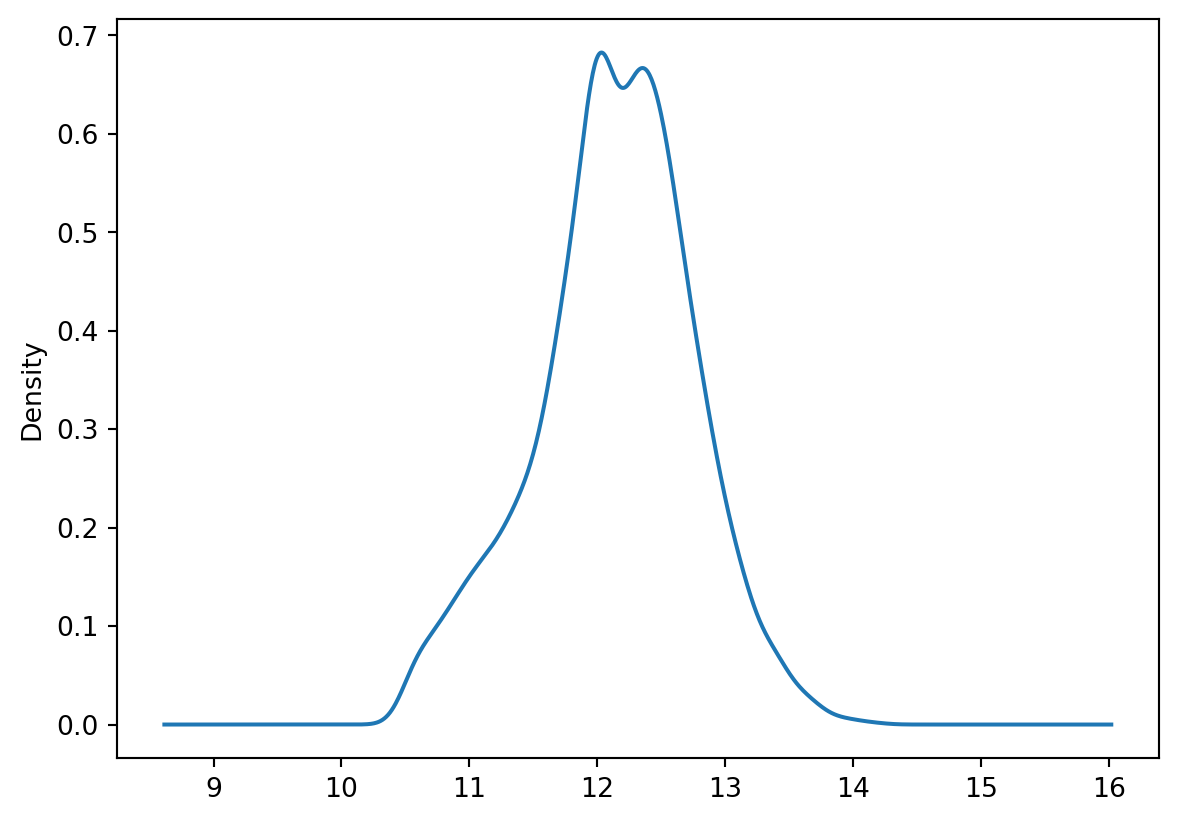
Dependent Variable : log_price Number of Observations: 5543
Mean dependent var : 12.1398 Number of Variables : 23
S.D. dependent var : 0.6173 Degrees of Freedom : 5520
R-squared : 0.7092
Adjusted R-squared : 0.7080
Sum squared residual: 614.174 F-statistic : 611.8131
Sigma-square : 0.111 Prob(F-statistic) : 0
S.E. of regression : 0.334 Log likelihood : -1767.840
Sigma-square ML : 0.111 Akaike info criterion : 3581.681
S.E of regression ML: 0.3329 Schwarz criterion : 3733.948
------------------------------------------------------------------------------------
Variable Coefficient Std.Error t-Statistic Probability
------------------------------------------------------------------------------------
CONSTANT 4.04140 0.23690 17.05941 0.00000
STRUGRAD 0.69245 0.02497 27.72919 0.00000
C(RESITYP)[T.TH] -0.15085 0.01428 -10.56169 0.00000
C(DESCCNST)[T.CNST 1/2 Brick Siding] -0.04637 0.07929 -0.58489 0.55865
C(DESCCNST)[T.CNST 1/2 Stone Frame] -0.48490 0.11735 -4.13202 0.00004
C(DESCCNST)[T.CNST 1/2 Stone Siding] 0.47431 0.24243 1.95646 0.05046
C(DESCCNST)[T.CNST Block] -0.00245 0.07200 -0.03407 0.97282
C(DESCCNST)[T.CNST Brick] -0.01114 0.05129 -0.21714 0.82810
C(DESCCNST)[T.CNST Frame] -0.01463 0.05196 -0.28151 0.77833
C(DESCCNST)[T.CNST Shingle Asbestos] 0.10916 0.05738 1.90237 0.05717
C(DESCCNST)[T.CNST Shingle Wood] 0.01447 0.06109 0.23689 0.81275
C(DESCCNST)[T.CNST Siding] 0.06409 0.05164 1.24092 0.21469
C(DESCCNST)[T.CNST Stone] 0.16488 0.07543 2.18594 0.02886
C(DESCCNST)[T.CNST Stucco] -0.00955 0.05711 -0.16721 0.86721
np.log(SQFTSTRC) 0.52471 0.01556 33.73058 0.00000
struc_age -0.00414 0.00052 -7.96012 0.00000
age_square 0.00002 0.00000 5.28951 0.00000
p_nonhisp_white_persons -0.00028 0.00024 -1.14453 0.25245
p_edu_college_greater 0.00547 0.00041 13.22243 0.00000
log_inc 0.22782 0.01771 12.86298 0.00000
p_housing_units_multiunit_structures 0.00225 0.00026 8.75894 0.00000
p_owner_occupied_units 0.00701 0.00051 13.75138 0.00000
log_jobaccess 0.03681 0.00552 6.66597 0.00000
------------------------------------------------------------------------------------
Warning: Variable(s) ['Intercept'] removed for being constant.
REGRESSION DIAGNOSTICS
MULTICOLLINEARITY CONDITION NUMBER 225.365
TEST ON NORMALITY OF ERRORS
TEST DF VALUE PROB
Jarque-Bera 2 802.382 0.0000
DIAGNOSTICS FOR HETEROSKEDASTICITY
RANDOM COEFFICIENTS
TEST DF VALUE PROB
Breusch-Pagan test 22 656.931 0.0000
Koenker-Bassett test 22 475.640 0.0000
DIAGNOSTICS FOR SPATIAL DEPENDENCE
- SARERR -
TEST MI/DF VALUE PROB
Moran's I (error) 0.1570 27.668 0.0000
Lagrange Multiplier (lag) 1 261.053 0.0000
Robust LM (lag) 1 49.614 0.0000
Lagrange Multiplier (error) 1 745.488 0.0000
Robust LM (error) 1 534.049 0.0000
Lagrange Multiplier (SARMA) 2 795.102 0.0000
- Spatial Durbin -
TEST DF VALUE PROB
LM test for WX 22 519.285 0.0000
Robust LM WX test 22 886.997 0.0000
Lagrange Multiplier (lag) 1 261.053 0.0000
Robust LM Lag - SDM 1 628.765 0.0000
Joint test for SDM 23 1148.050 0.0000
================================ END OF REPORT =====================================
The estimated model coefficients are the same between packages, but using spreg, we get a full suite of spatial diagnostics in the resulting summary, all of which are highly significant. These results show overwhelming evidence our model should account for some kind of spatial dependence, but since all the tests are significant, we need more exploration to understand which model is most appropriate. So we will step-up our spatial models one at a time, following Anselin (2007). Further, as with the statsmodels result, the Jarque-Bera test of normality on the residuals is highly significant, which could indicate we need to use a robust estimator.
30.3.2 Spatial Lag-of-X (SLX)
To fit an SLX model using the same spatial weights matrix for the dependent variable and every independent variable, you can simply use spreg’s OLS class and pass a Graph, and the argument slx_lags=1, which indicates that the model should include a \(WX\) variable for each of the explanatory variables in the model formula (design matrix). This fits the model:
In addition to the summary attribute, which stores a large textual report, the output attribute of each spreg class stores the estimated coefficients and significance measures as a pandas DataFrame. In this output, we can see each of the \(X\) variables in the original specification now also has a \(WX\) version (prefixed by W_), many of which are significant. These results show clear and substantive evidence of spatial spillover (especially for neighborhood income W_loginc, which has a very large coefficient), where attributes of observations nearby influence the outcome at a different location.
Code
print(f"Robust LM Error p-value: {model_slx.rlm_error[1]}")print(f"Robust LM Lag p-value: {model_slx.rlm_lag[1]}")
Robust LM Error p-value: 0.0025532603356221394
Robust LM Lag p-value: 0.00013605719519529572
Despite significant \(WX\) results, the robust Lagrange Multiplier tests for both the SEM and SAR models are highly significant, showing significant autocorrelation remaining in the residual and suggesting we still need to explore more models.
30.3.3 Spatial Error (SEM)
To fit the spatial error model it is best to use the GMM_Error class, which fits the model:
\[y = \beta X + u\]\[ u = \lambda Wu+ \epsilon \]
Note
Classic estimation for spatial econometric models uses Maximum-Likelihood (ML), but modern applications typically prefer Generalized Method of Moments (GMM) for spatial error variants and Two-Stage Least Squares (TSLS) estimation for lag-based models, both of which are faster and applicable to larger datasets. Below, we will only use the spreg classes based on these estimators, however this is important to know, because TSLS estimation uses higher-order spatial lags of the X variables as instruments for estimating \(\rho WY\) by default. This will cause problems when estimating models that also include lagged \(X\)-variables (i.e. SLX-Error and Spatial Durbin). To avoid these errors, you can provide alternative instruments yourself, or you can pass w_lags >=2 which uses even higher-order neighbors as instruments.
Following the same conventions as above, we pass y, X, and W, then examine the output. Since the OLS model also showed some evidence of heteroskedasticity in the errors, we will also use a robust estimator by passing estimator="het".
In these results, we now have a lambda coefficient for our spatial error term, which is highly significant (and pretty large at 0.66). Most \(X\) variables related to the building structure are still significant, and now the neighborhood racial composition becomes significant. The rest of the significant coefficients have changed values a bit, for example the log_inc coefficient is reduced to 0.142 (down from 0.228 in the OLS model).
30.3.4 Spatial Lag (SAR)
To fit a spatial lag model the preferred approach is to use the GM_Lag class, which uses TSLS under the hood. If you have additional instruments to use, you can pass them to yend, but here we will adopt the default (which computes then uses \(WX\) as instruments). For robustness, we will also include White standard errors.
Compared to the SEM, this model has a slightly better model fit, and some of the coefficients have changed a bit. The spatial autoregressive parameter called W_dep_var in the report is relatively small but highly significant. Racial composition in the neighborhood is no longer significant, and the neighborhood income coefficient has increased again up to 0.20.
The summary for models that include lagged dependent variables is also slightly different, as the end of the summary table now includes a set of impacts for each explanatory variable that show the direct, indirect, and total effects associated with each input. Thus we can see the total impact of neighborhood income is actually even higher at 0.23 after accounting for spillover effects. The Anselin-Kelejian test for spatial dependence is still significant in this model (Anselin & Kelejian, 1997), which suggests we may need to use an even more general model like the Spatial Durbin.
30.3.5 SLX-Error (SLXE / Durbin-Error)
To fit an SLXE model, we use the GMM_Error class once again, but this time pass slx_lags=1, which automatically handles the creation and inclusion of our \(WX\) variables.
With this result, we have both a lambda coefficient (which remains significant and large, though a bit smaller) and a series of W_ coefficients as with the SLX specification.
Notice in the report for the Durbin model the instrumented variable (W_dep_var) is estimated using instruments prefixed with W2_ indicating second-order spatial lags of the explanatory variables. That is, the GM_Lag class noticed we included slx_lags=1 and automatically incremented the order of \(WX\) to use as instruments. Obviously, you can modify this behavior or pass your own instruments if desired.
30.3.7 Comparison
Sometimes it can be useful to compare the estimated coefficients from each model side-by-side, but until now we’ve had them each in separate summaries. For simplicity, we can concatenate the output tables from each of the models, and we can make sure everything stays aligned by setting the variable as an index.
These models have different sets of terms (e.g. only SEM variants have lambda, only SLX variants have W_ variables, and only Lag variants have W_dep_var), so models missing the necessary coefficients will have NAs. Also remember that we’re joining together only the output from the lag models, not the impacts, so we are ignoring the indirect effects from these models.
Comparing the estimated coefficients shows that median income was doing a lot of heavy lifting in the OLS model. That is, when we ignore spatial effects, the median income variable absorbs a lot of the spatial variance, inflating its coefficient and biasing our interpretation of how much residents value higher-income neighbors. In the spatial models, the estimated coefficient for income is less than half as large. That’s basically true of all the other neighborhood characteristics as well.
Remember that our data are measured at two different spatial levels. Our housing sales are measured at the unit level, but the ‘neighborhood’ variables are measured at the census blockgroup level. Because we have several sales nested inside each census unit, we are building spatial autocorrelation into the model by design. That is, because we don’t know the income, education, race, etc of the home’s previous owner, the “neighborhood” variables coming from the Census are defined in geographic zones which are essentially \(WX\) instead of just \(X\), where \(W\) is defined by discrete membership inside a census unit.
30.4 Specification Search
In general, it is a good idea to fit a series of models and examine them one at a time using both diagnostics and available theory, as we do above. However spreg also offers a set of tools for automated model specification search following the selection criteria outlined in Anselin et al. (2024) in the spsearch submodule. These functions proceed by fitting a series of models, selecting the chosen alternative based on a set of tests defined by each search strategy defined by Anselin et al. (2024), and each returns the name and instance of the best-fitting model.
30.4.1 Specific to General
The specific-to-general strategy (STG) moves through the same process as above, starting with restrictive models that do not include spatial terms, then moving to increasingly complex specifications as necessary (indicated by failing spatial diagnostics for simpler models). The search strategies differ in the starting models or the preferred metric for comparing models. Below we carry out all three search strategies and store the best model inside a pandas Series for presentation. As a small matter of housekeeping, the spsearch functions do not automatically drop the intercept column on our design matrix X before adding its own constant (unlike the classes invoked directly above), so we need to do this step manually.
Classic ERROR_Br
Koley-Bera SDM
Pre LAG
dtype: object
To make things difficult, the search strategies disagree on their preferred model(!) the classic search suggests (robust) SEM, the ‘pre’ search suggests the SAR model, and the KB search suggests the SDM. In this case, I would argue the results suggest the preferred specification from the STG approach is the Spatial Durbin model, because this specification is preferred by the most modern diagnostic statistics, (Koley & and Bera, 2024; Koley & Bera, 2022), and the SDM specification has some useful conceptual properties as described by LeSage & Pace (2009).
30.4.2 General to Specific
Alternatively, we could adopt a general-to-specific (GTS) search strategy where we begin with over-specified models that include all spatial terms, then systematically simplify these models by removing spatial components deemed unnecessary. In this case, we can begin with either the SDM or the general nesting specification (GNS) (which we do not actually bother fitting above, given its issues with identification and interpretation).
Both of the top-down search strategies prefer the SARSAR (spatial combo) model which includes a spatially-lagged dependent variable and spatially-lagged error term (reflecting the fact that there is still significant autocorrelation in the residual of the spatial Durbin model).
30.5 Extensions
The spreg package also includes a wide variety of additional models we do not explore here, including spatial Seemingly Unrelated Regression (SUR), spatial Panel models (Elhorst, 2003, 2014), and diagnostics for Probit and non-linear models.
30.5.1 Regimes
In all of the examples above, we assume the relationship between \(X\) and \(y\) is constant over space. In some applications, however, there may be reason to believe that coefficients vary over the study region, i.e. there are different “treatment regimes” (Imai & van Dyk, 2004). Rather than estimate a separate regression for every data point a-la GWR, one way to handle spatially-varying relationships in a spatial econometric framework is through the use of spatial regimes which separate the study region into discrete portions (defined by a different \(W\) matrix), then fit separate models for each portion (Durlauf & Johnson, 1995). This is a bit like the geographic version of piecewise regression, where geographic zones are used to define the breakpoints rather than ranges of the outcome variable. Each of the models above optionally takes a regime argument that defines the grouping for each observation. Alternatively, spreg also offers a function for determining optimal regimes endogenously by combining SKATER constrained clustering with spatial regression, following Anselin & Amaral (2023).
30.5.2 Quasi Experiments and Causal Designs
A prominent critique of applied spatial econometric modeling is given by Gibbons & Overman (2012), who argue that the suite of models above
does not provide a toolbox that gives satisfactory solutions to these problems for applied researchers interested in causality and the economic processes at work. It is in this sense that we call into question the approach of the burgeoning body of applied economic research that proceeds with mechanical application of spatial econometric techniques to causal questions of “spillovers” and other forms of spatial interaction, or that estimates spatial lag models as a quick fix for endogeneity issues, or that blindly applies spatial econometric models by default without serious consideration of whether this is necessary given the research question in hand.
To overcome these issues, they argue that applied work should adopt what they term ‘experimentalist’ design4, where some form of exogenous variation is induced to provide insight into a causal mechanism at play. Spatial econometric models that incorporate quasi experimental designs are an active area of research, with early pioneering work by Dubé et al. (2014), Delgado & Florax (2015), Bardaka et al. (2018), and Diao et al. (2017), who blend different spatial specification above with a difference-in-differences framework. While this work represents an important step forward from traditional designs that ignore spatial dependence altogether, the complexity involved with DID designs that include spatial terms is still under-appreciated, and many important issues in urban policy analysis do not have a satisfactory specification using such an approach (Knaap, 2024).
Alternatively, structural models5 should proceed by considering the SLX model as the point of depatrture, or use strong theory to guide the choice of a particular specification as described above (Halleck Vega & Elhorst, 2015). Although there remains debate in urban economics, I believe there is a good justification for assuming a potential autoregressive process in the specific context of hedonic housing price models.
Abadie, A., Athey, S., Imbens, G. W., & Wooldridge, J. M. (2020). Sampling‐Based versus Design‐Based Uncertainty in Regression Analysis. Econometrica, 88(1), 265–296. https://doi.org/10.3982/ECTA12675
Anselin, L., Bera, A., Florax, R. J. G. M., & Yoon, M. (1996). Simple diagnostic tests for spatial dependence. Regional Science and Urban Economics, 26, 77–104. https://doi.org/10.1016/0166-0462(95)02111-6
Anselin, L., & Kelejian, H. H. (1997). Testing for spatial error autocorrelation in the presence of endogenous regressors. International Regional Science Review, 20(1), 153–182. https://doi.org/10.1177/016001769702000109
Anselin, L., & Rey, S. J. (2014). Modern spatial econometrics in practice: A guide to GeoDa, GeoDaSpace and PySAL. GeoDa Press.
Bardaka, E., Delgado, M. S., & Florax, R. J. G. M. (2018). Causal identification of transit-induced gentrification and spatial spillover effects: The case of the Denver light rail. Journal of Transport Geography, 71, 15–31. https://doi.org/10.1016/j.jtrangeo.2018.06.025
Borusyak, K., Hull, P., & Jaravel, X. (2024). Design-based identification with formula instruments: A review. The Econometrics Journal, utae003. https://doi.org/10.1093/ectj/utae003
Delgado, M. S., & Florax, R. J. G. M. (2015). Difference-in-differences techniques for spatial data: Local autocorrelation and spatial interaction. Economics Letters, 137, 123–126. https://doi.org/10.1016/j.econlet.2015.10.035
Diao, M., Leonard, D., & Sing, T. F. (2017). Spatial-difference-in-differences models for impact of new mass rapid transit line on private housing values. Regional Science and Urban Economics, 67, 64–77. https://doi.org/10.1016/j.regsciurbeco.2017.08.006
Dubé, J., Legros, D., Thériault, M., & Des Rosiers, F. (2014). A spatial Difference-in-Differences estimator to evaluate the effect of change in public mass transit systems on house prices. Transportation Research Part B: Methodological, 64, 24–40. https://doi.org/10.1016/j.trb.2014.02.007
Durlauf, S. N., & Johnson, P. A. (1995). Multiple regimes and cross-country growth behavior. Journal of Applied Econometrics, 10, 365–384. https://doi.org/10.1002/jae.3950100404
Elhorst, J. P. (2003). Specification and Estimation of Spatial Panel Data Models. International Regional Science Review, 26(3), 244–268. https://doi.org/10.1177/0160017603253791
Halleck Vega, S., & Elhorst, J. P. (2015). THE SLX MODEL. Journal of Regional Science, 55(3), 339–363. https://doi.org/10.1111/jors.12188
Imai, K., & van Dyk, D. A. (2004). Causal Inference With General Treatment Regimes. Journal of the American Statistical Association, 99(467), 854–866. https://doi.org/10.1198/016214504000001187
Juhl, S. (2021). The Wald Test of Common Factors in Spatial Model Specification Search Strategies. Political Analysis, 29(2), 193–211. https://doi.org/10.1017/pan.2020.23
Knaap, E. (2024, February 24). Measuring the Purple Line’s Effect on Residential Rents: Spatial Econometrics and Causal Inference in Urban Policy Analysis (SSRN Scholarly Paper No. 4737294). https://doi.org/10.2139/ssrn.4737294
Koley, M., & and Bera, A. K. (2024). To use, or not to use the spatial Durbin model? – that is the question. Spatial Economic Analysis, 19(1), 30–56. https://doi.org/10.1080/17421772.2023.2256810
Koley, M., & Bera, A. (2022, March 4). Testing for Spatial Dependence in a Spatial Autoregressive (SAR) Model in the Presence of Endogenous Regressors (SSRN Scholarly Paper No. 4050145). https://papers.ssrn.com/abstract=4050145
LeSage, J. P. (2014). What Regional Scientists Need to Know About Spatial Econometrics. SSRN Electronic Journal. https://doi.org/10.2139/ssrn.2420725
LeSage, J. P., & Pace, R. K. (2014). Interpreting Spatial Econometric Models. In Handbook of Regional Science (pp. 1535–1552). Springer Berlin Heidelberg. https://doi.org/10.1007/978-3-642-23430-9_91
LeSage, J., & Pace, R. K. (2009). Introduction to Spatial Econometrics. CRC Press.
Manski, C. F., & McFadden, D. (Eds.). (1981). Structural analysis of discrete data with econometric applications. MIT Press.
Rey, S. J., & Anselin, L. (2010). PySAL: A Python Library of Spatial Analytical Methods. In Handbook of Applied Spatial Analysis (Vol. 37, pp. 175–193). Springer Berlin Heidelberg. https://doi.org/10.1007/978-3-642-03647-7_11
Rey, S. J., Anselin, L., Amaral, P., Arribas-Bel, D., Cortes, R. X., Gaboardi, J. D., Kang, W., Knaap, E., Li, Z., Lumnitz, S., Oshan, T. M., Shao, H., & Wolf, L. J. (2021). The PySAL Ecosystem: Philosophy and Implementation. Geographical Analysis, gean.12276. https://doi.org/10.1111/gean.12276
Rubin, D. B. (2005). Causal Inference Using Potential Outcomes. Journal of the American Statistical Association, 100(469), 322–331. https://doi.org/10.1198/016214504000001880
Wilkinson, G. N., & Rogers, C. E. (1973). Symbolic Description of Factorial Models for Analysis of Variance. Journal of the Royal Statistical Society. Series C (Applied Statistics), 22(3), 392–399. https://doi.org/10.2307/2346786
Witte, A. D., Sumka, H. J., & Erekson, H. (1979). An Estimate of a Structural Hedonic Price Model of the Housing Market: An Application of Rosen’s Theory of Implicit Markets. Econometrica, 47(5), 1151. https://doi.org/10.2307/1911956
Despite the preferences of LeSage & Pace (2009), Anselin et al. (2024) use the reduced form of the unrestricted SDM to show that “there is no solid theoretical basis for preferring one specification over the other, only an empirical one.”↩︎
Using different arguments in the spreg classes allows one to fit all of the models described in previous sections, and the Wilkinson formula need not be changed for these specifications. It is also possible to fit increasingly complex models, e.g. where different explanatory variables are defined by different spatial scopes (\(W_1X_1, W_2 X_2\), etc.) (Galster, 2019), but these kinds of specifications need to be created manually e.g. by creating \(WX\) variables on the dataframe using the Graph.lag(x) convention. In this case, a user would want to specify these terms directly in Wilkinson formulas, and avoid using the slx_vars argument in spreg which applies the same Graph specification to each \(X\) variable.↩︎