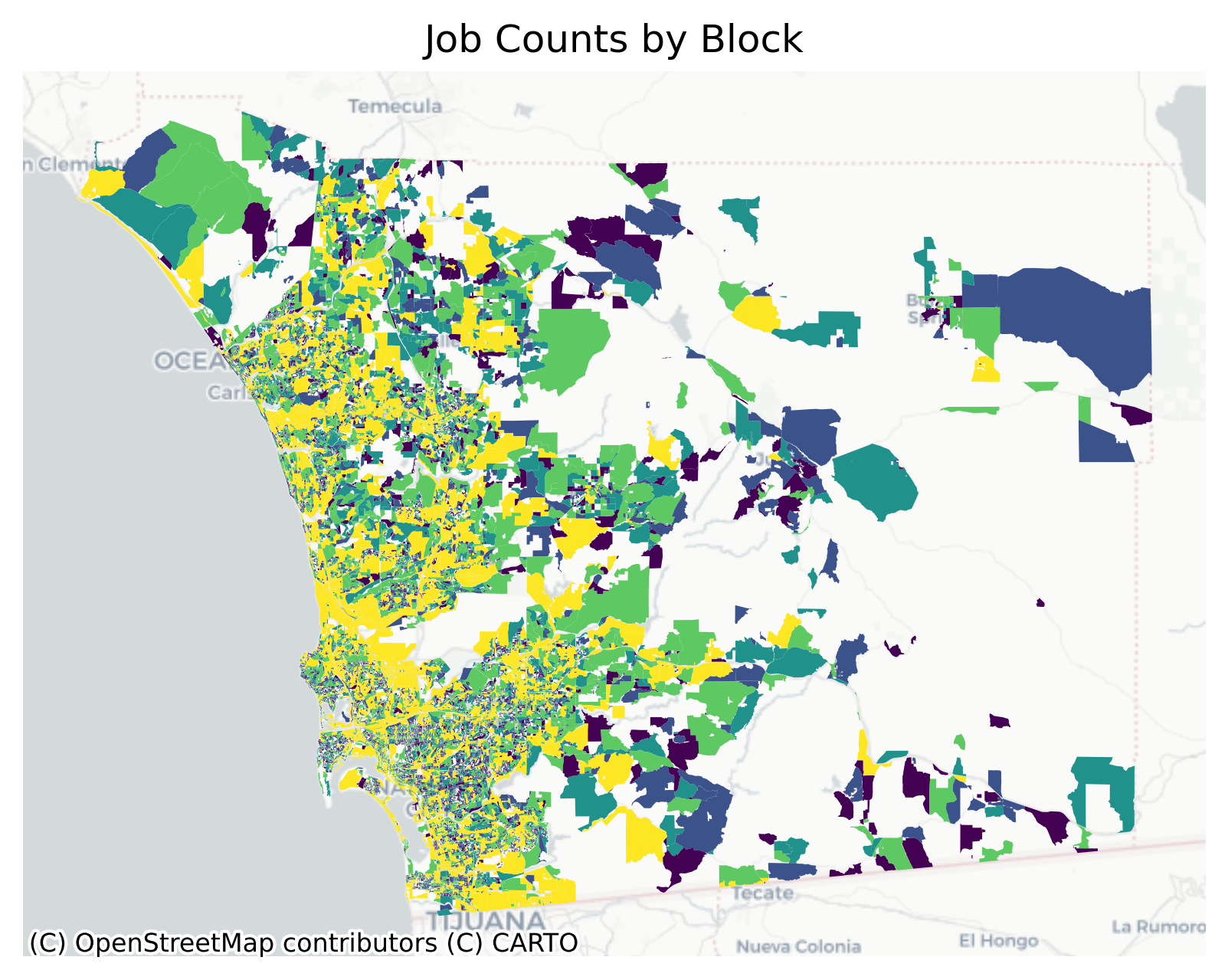
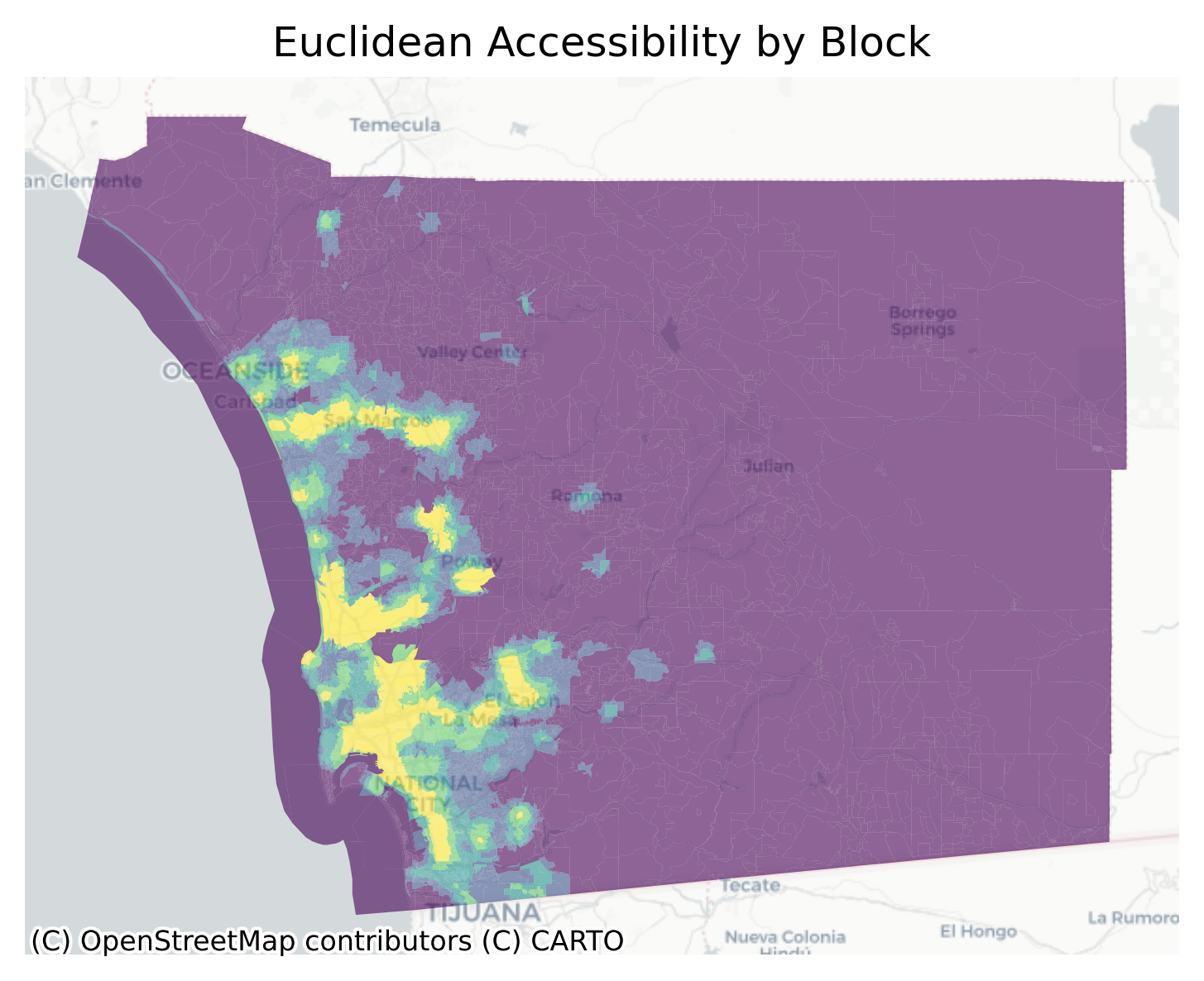
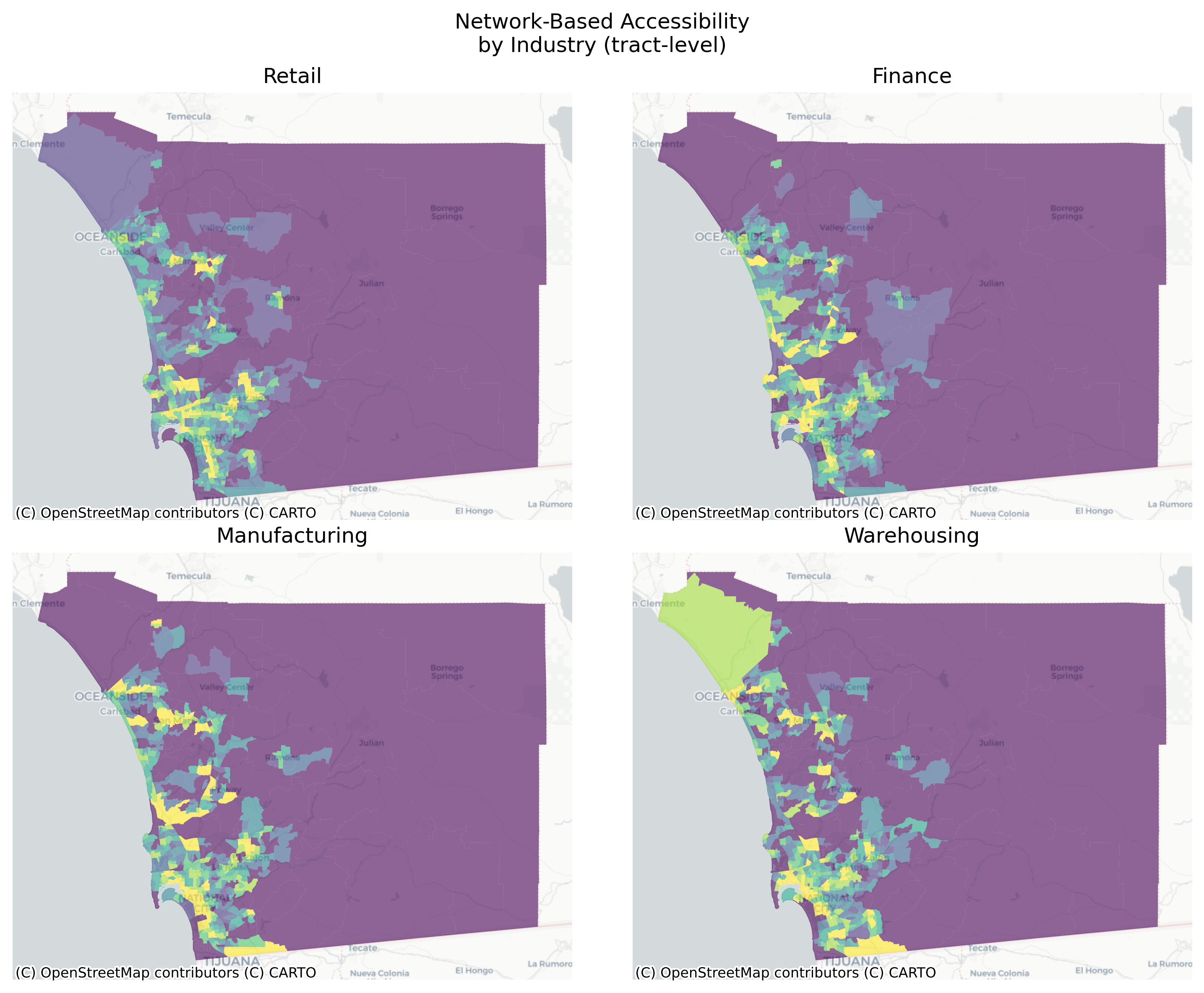
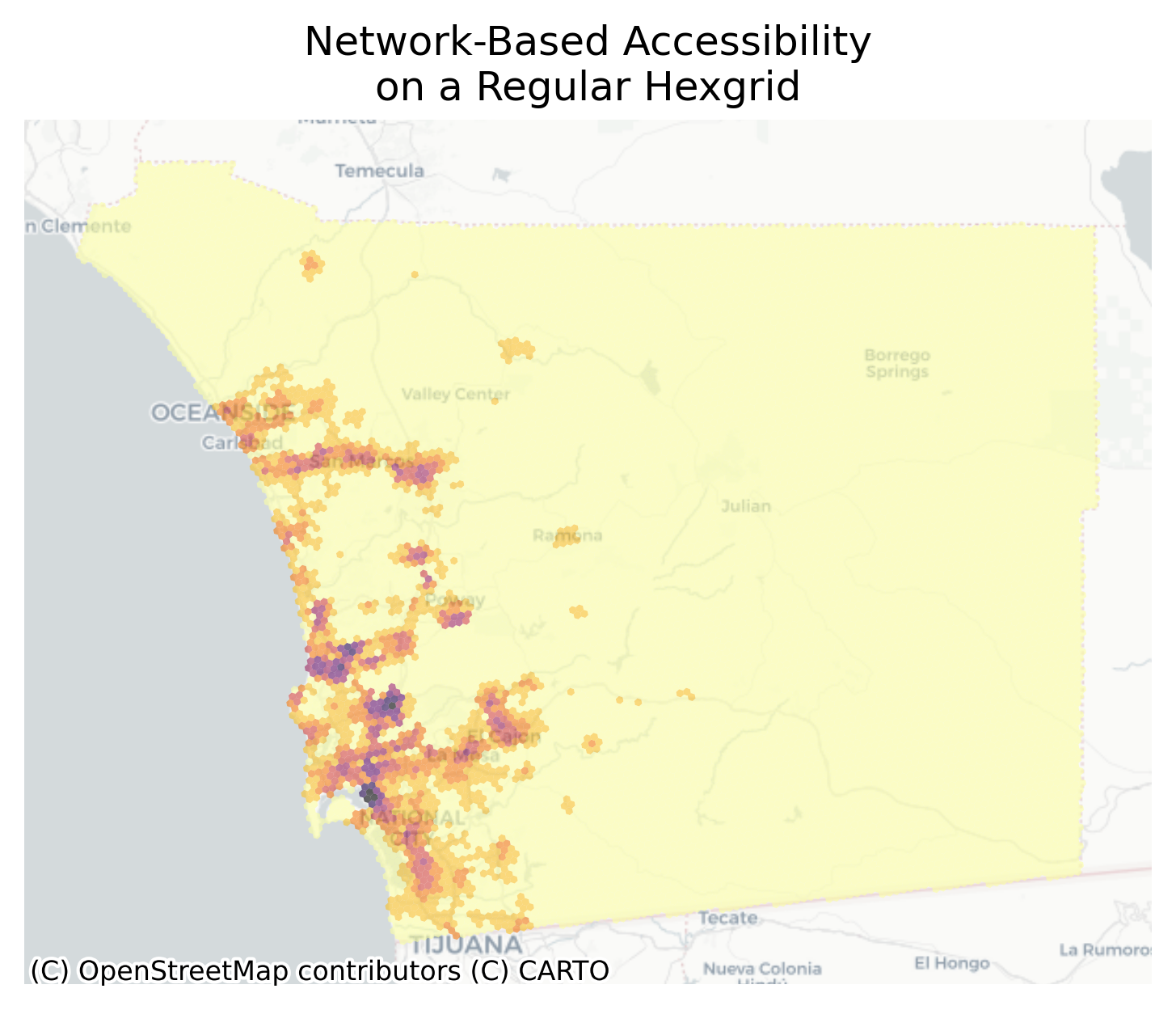
Code
import contextily as ctx
import geopandas as gpd
import mapclassify as mc
import matplotlib.pyplot as plt
import numpy as np
import pandarm as pdna
import pandas as pd
import pydeck as pdk
import quilt3 as q3
from geosnap import DataStore
from geosnap import analyze as gaz
from geosnap import io as gio
from libpysal.graph import Graph
from matplotlib import cm
from matplotlib.colors import Normalize
from tobler.util import h3fy
from mapclassify.util import get_color_array
%load_ext watermark
%watermark -a 'eli knaap' -ivOMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.Author: eli knaap
pandarm : 0.0.0
pandas : 2.3.3
geopandas : 1.1.1
contextily : 1.6.2
pydeck : 0.9.1
libpysal : 4.13.0
mapclassify: 2.10.0
tobler : 0.12.1
numpy : 2.3.5
matplotlib : 3.10.8
geosnap : 0.15.3
quilt3 : 7.0.0