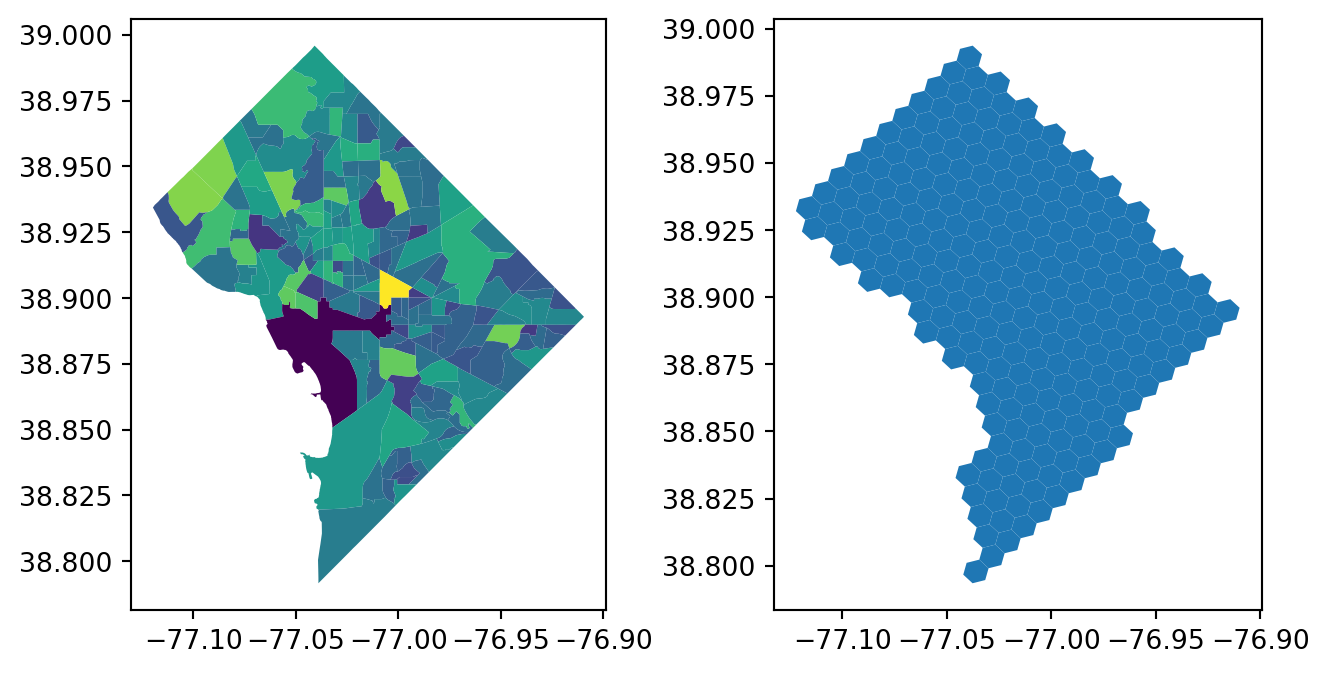
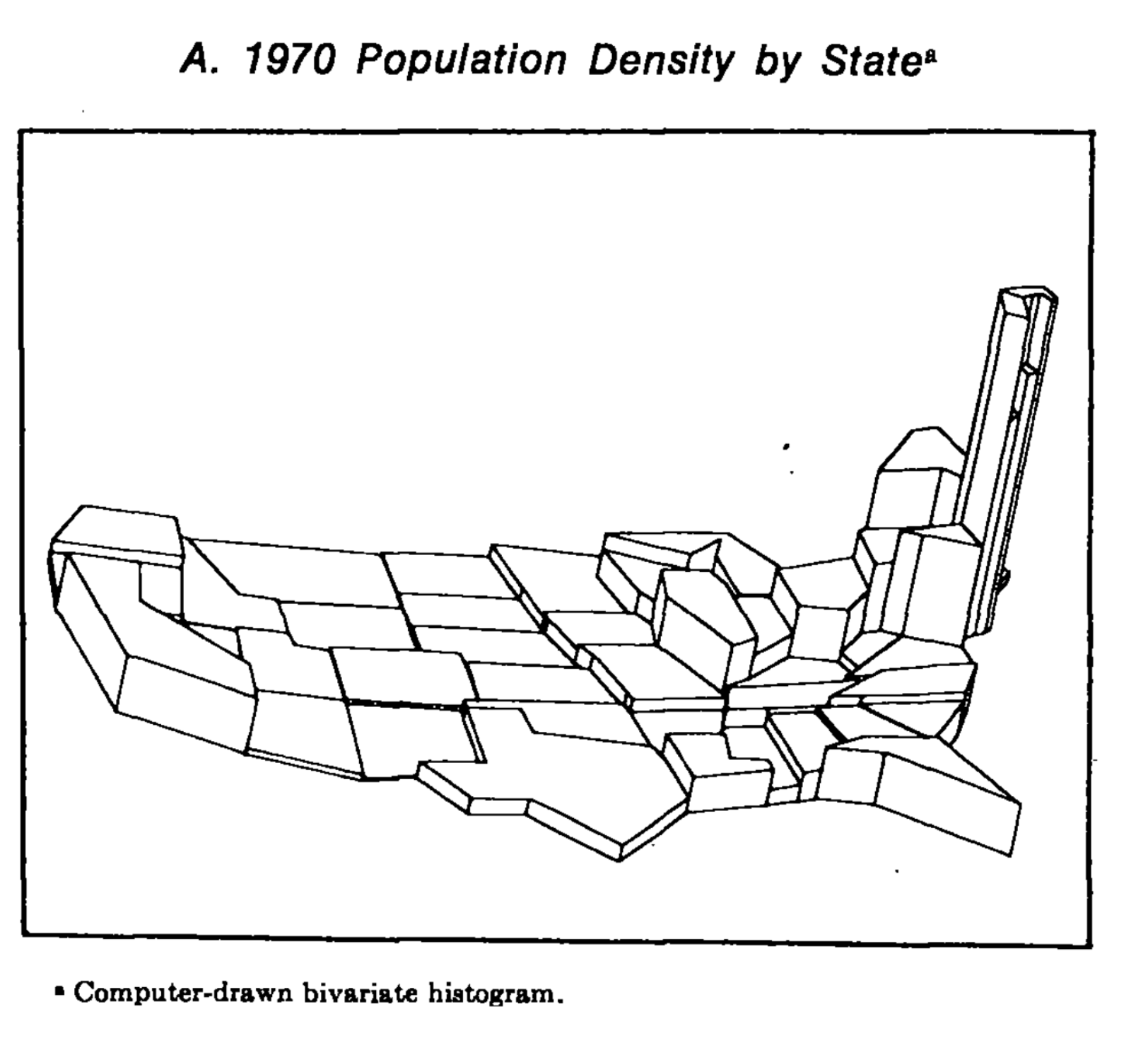
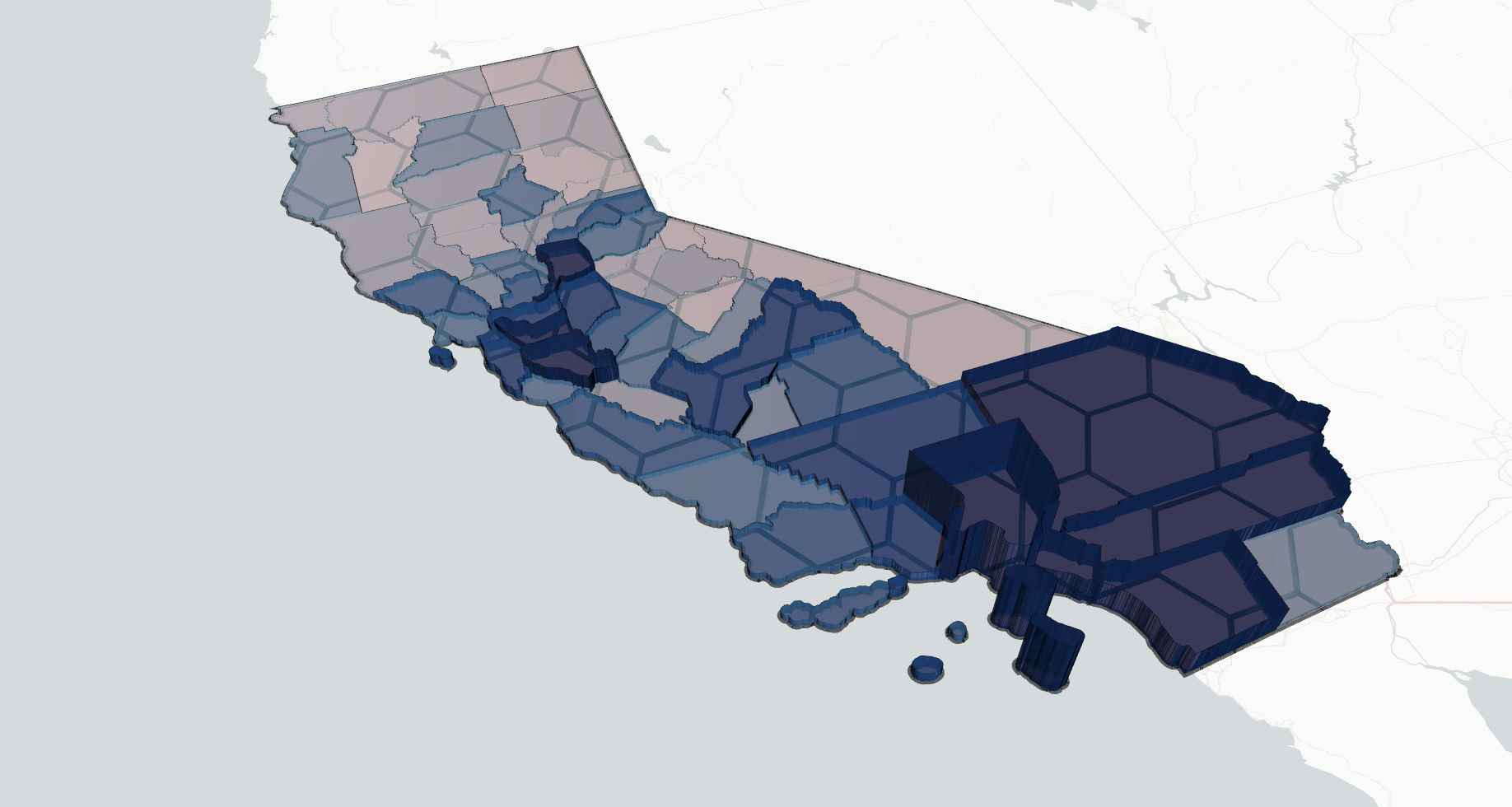
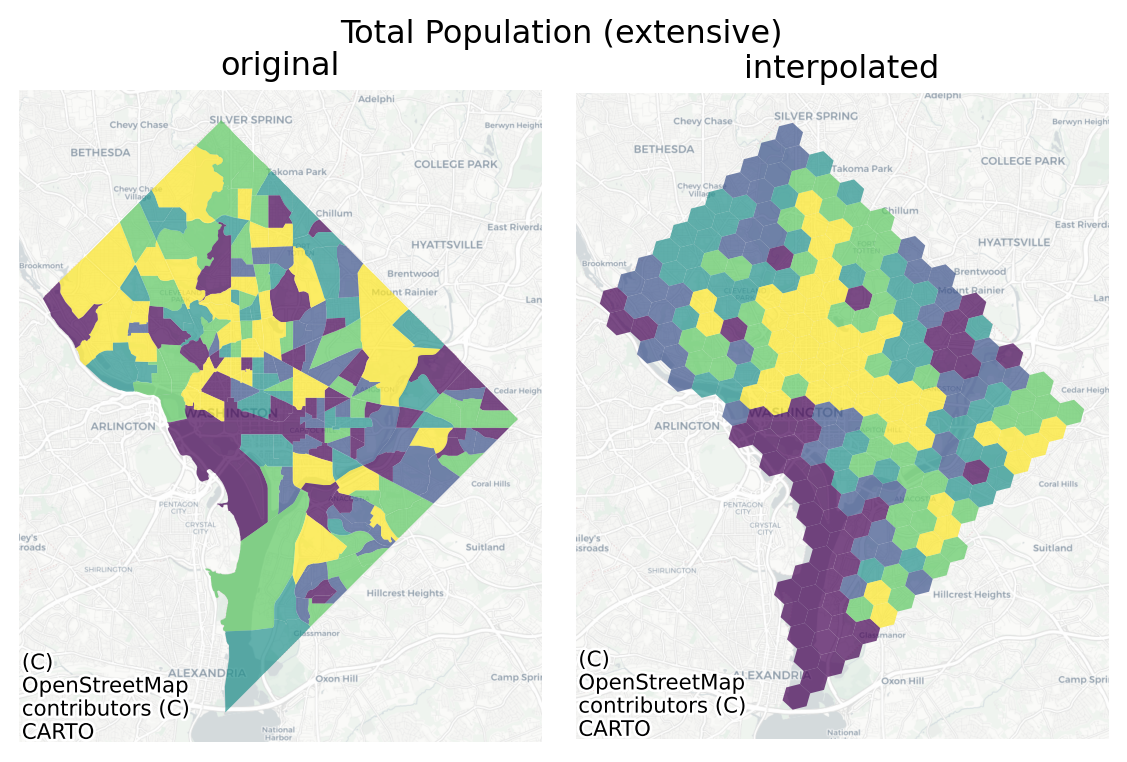
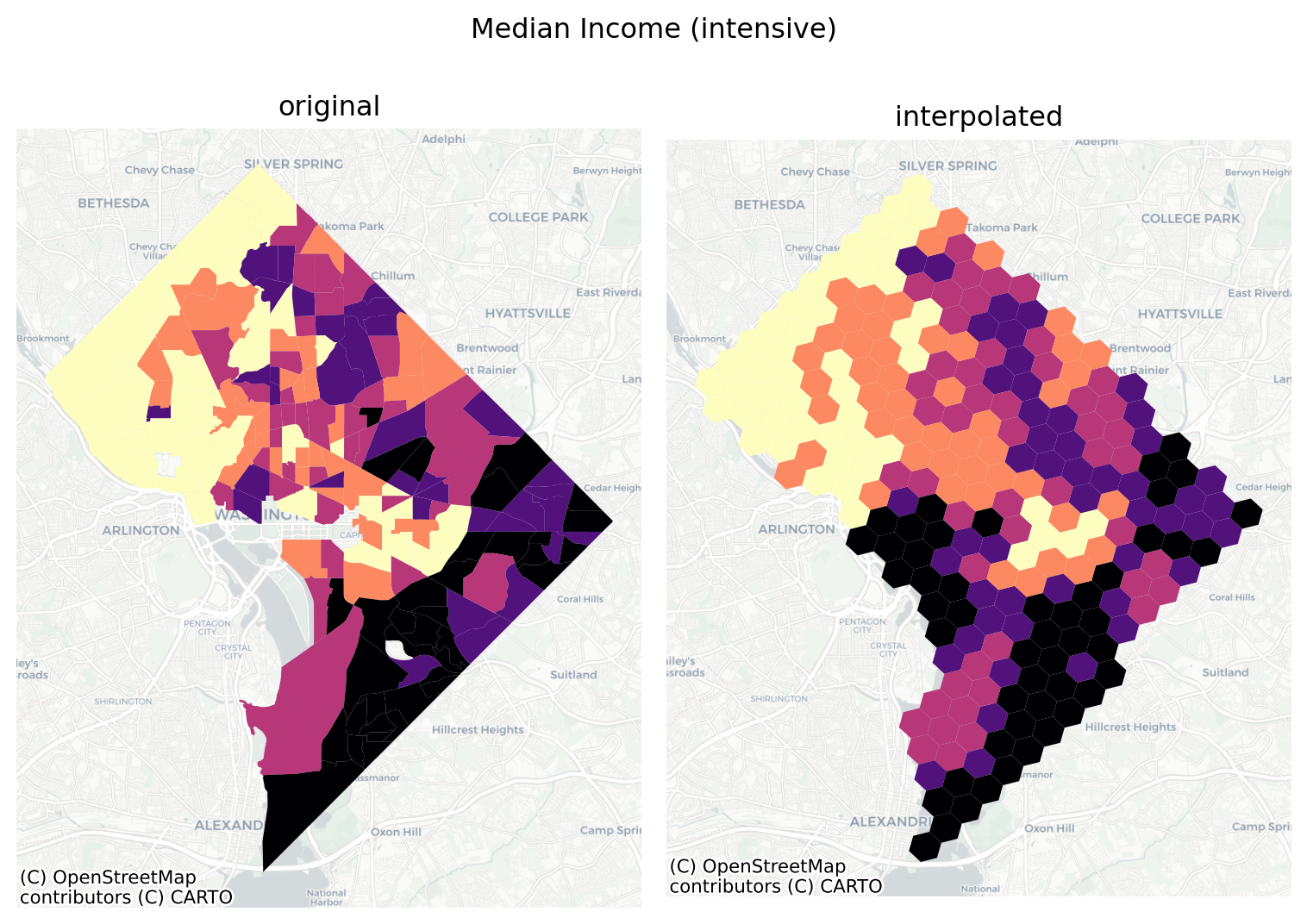
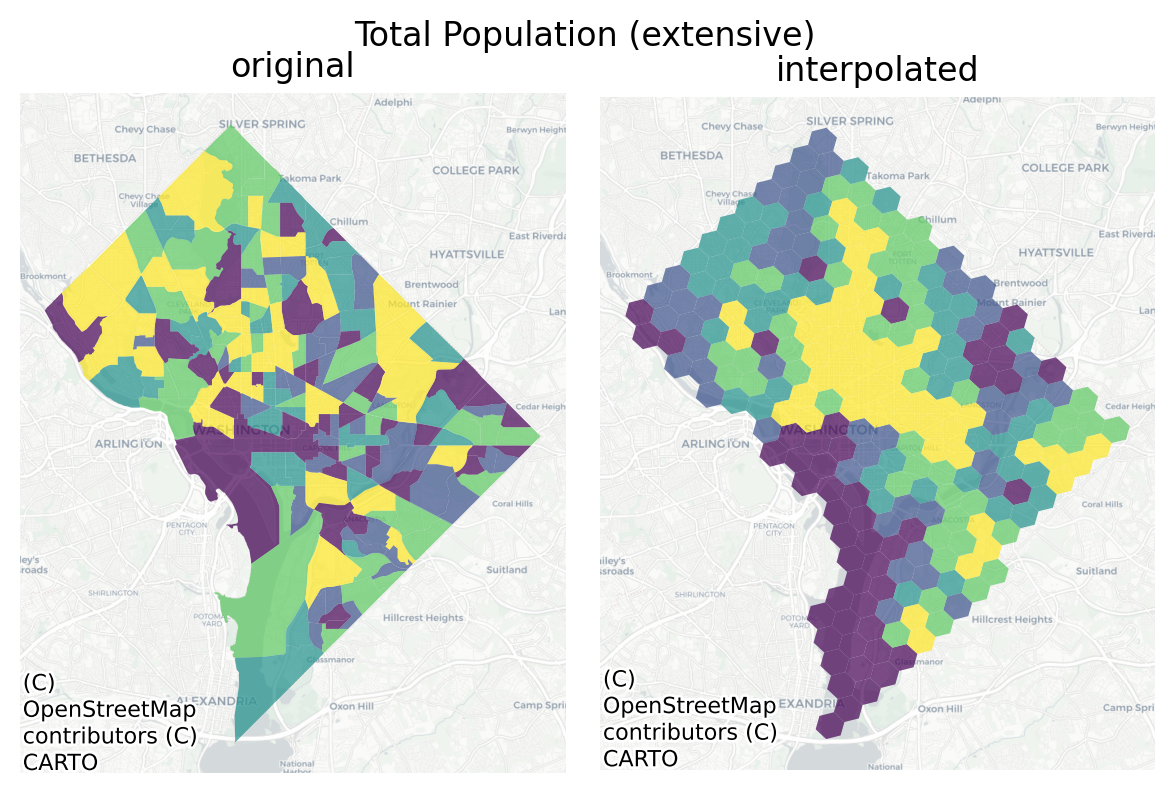
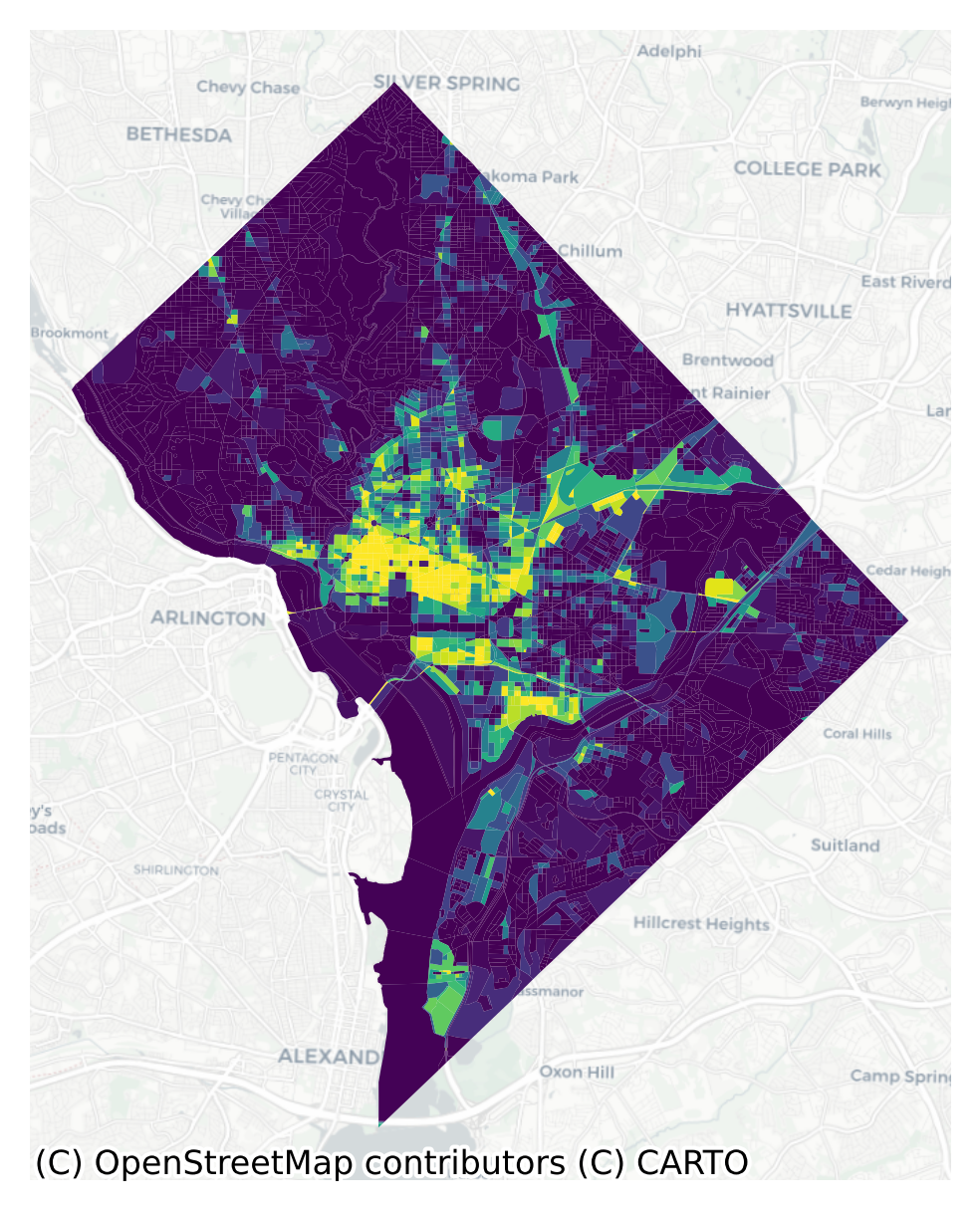
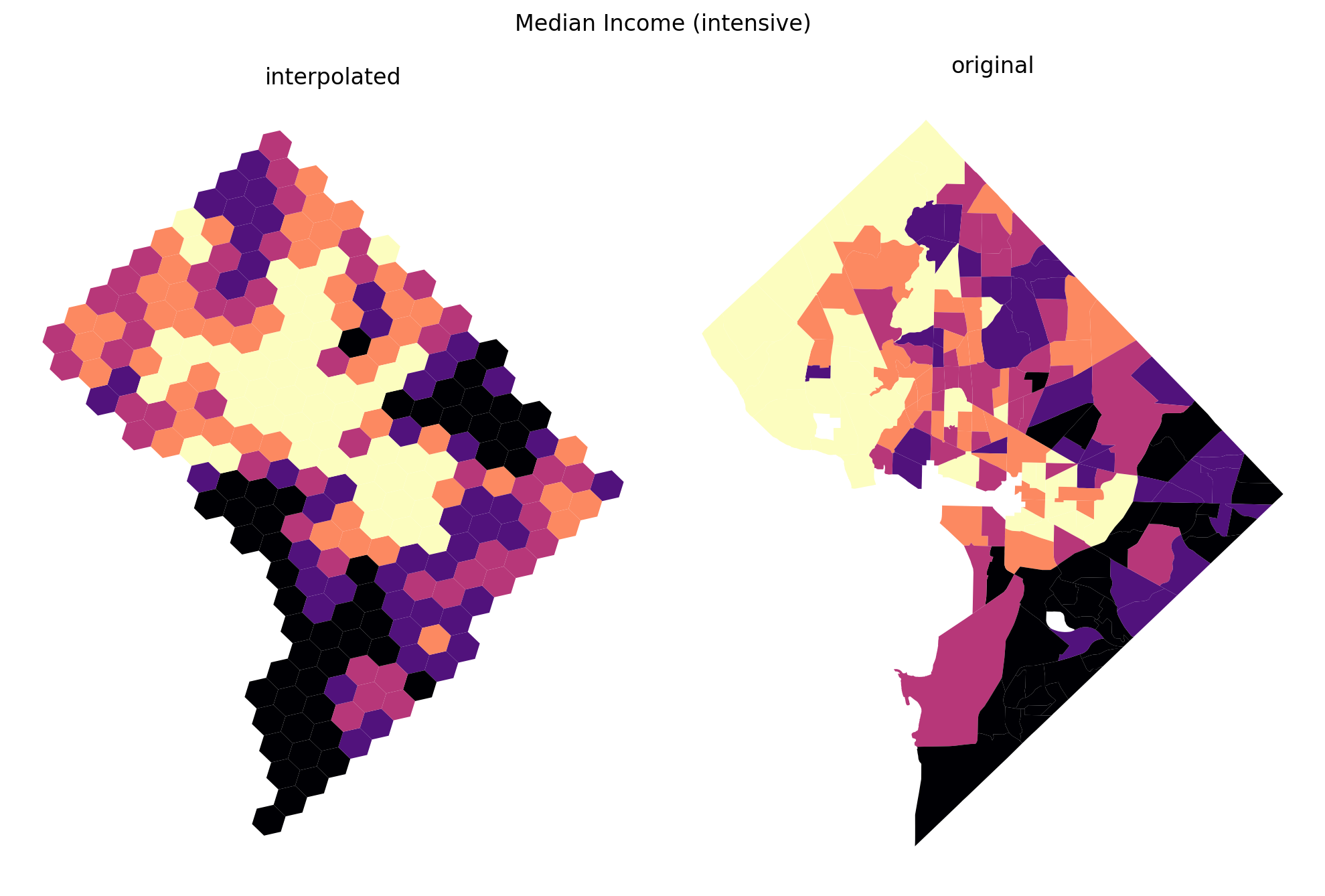
Code
import contextily as ctx
import geopandas as gpd
import geoviews as gv
import pandas as pd
import hvplot.pandas
import matplotlib.pyplot as plt
import numpy as np
import pydeck as pdk
from geosnap import DataStore
from geosnap import io as gio
#from lonboard import Map, PolygonLayer, viz
from mapclassify.util import get_color_array
from tobler.area_weighted import area_interpolate
from tobler.dasymetric import masked_area_interpolate, extract_raster_features
from tobler.pycno import pycno_interpolate
from tobler.util import h3fy
from matplotlib.colors import to_hex
from matplotlib.lines import Line2D
from matplotlib.patches import Patch
%load_ext jupyter_black
%load_ext watermark
%watermark -a 'eli knaap' -ivOMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.Author: eli knaap
numpy : 2.3.5
contextily : 1.6.2
geosnap : 0.15.3
matplotlib : 3.10.8
tobler : 0.12.1
pandas : 2.3.3
pydeck : 0.9.1
hvplot : 0.12.1
mapclassify: 2.10.0
geoviews : 1.15.0
geopandas : 1.1.1