Here, we’ll start with no data and build a simple CA model with a single transition rule using a spatial Markov framework. That is, the probability of a unit transitioning into different uses is a probabilistic function of its current state, and the states of the units around it. Using data from NLCD, we can observe how often these transitions occurred in the past, including how those transitions are conditioned by different spatial contexts. Then we can use that model to simulate conditions into the future.
26.1 Data
Start by grabbing tract-level data for the Detroit-ish region
Make this Notebook Trusted to load map: File -> Trust Notebook
Now, create a regular hexagonal grid that covers the same area and convert the land cover data from NLCD from a raster into a vector, collapsing contiguous cells into regions. Then, we create a mapping between the pixel values to their descriptive names, for example pixel value 21 corresponds to “Developed, Open Space”.
Now aggregate the pixels into the (coarser) hexgrid and include a column of colors to match the conventions in land use mapping. First we define a small helper function, then apply it to the column of pixel values, resulting in a hex color for each land-use type (hexcolors are much easier to work with in this context because a hexcode is a single string whereas a RGBA representation is a tuple of values, which can be difficult to represent in a table).
Code
def img_to_hex(hexes, img_path, year): hexes = hexes.copy()# take the LULC image and convert from raster to vector lulc = extract_raster_features(hexes, img_path)# convert to a string for easier representation as categorical variable lulc["value"] = lulc["value"].astype(int).astype(str)# pixel value 255 is NA lulc["value"] = lulc["value"].replace({"255": np.nan}) temp = gpd.sjoin(lulc.to_crs(hexes.crs), hexes) temp = ( temp.groupby("hex_id")["value"].agg(lambda x: pd.Series.mode(x)[0]).astype(str) ) # cheat and take the min when multiple modes are returned... hexes = hexes.join(temp) hexes["year"] = year hexes["value"] = hexes["value"].replace(lu_mapper).replace({"nan": np.nan}) hexes = hexes.dropna()return hexesnlcd_colors = pd.read_csv("nlcd_colors.csv",)# convert rgb to 0-1 rangenlcd_colors.color = nlcd_colors.color.apply(lambda x: np.array(x.split(",")).astype(float) /255)# convert rgb to hex (easier to hold a single value in a column instead of a listnlcd_colors.color = nlcd_colors.color.apply(lambda x: to_hex(x))nlcd_colors
code
color
description
0
11
#466b9f
Open Water
1
12
#d1def8
Perennial Snow/Ice
2
21
#dec5c5
Developed, Open Space
3
22
#d99282
Developed, Low Intensity
4
23
#eb0000
Developed, Medium Intensity
5
24
#ab0000
Developed High Intensity
6
31
#b3ac9f
Barren Land (Rock/Sand/Clay)
7
41
#68ab5f
Deciduous Forest
8
42
#1c5f2c
Evergreen Forest
9
43
#b5c58f
Mixed Forest
10
52
#ccb879
Shrub/Scrub
11
71
#dfdfc2
Grassland/Herbaceous
12
81
#dcd939
Pasture/Hay
13
82
#ab6c28
Cultivated Crops
14
90
#b8d9eb
Woody Wetlands
15
95
#6c9fb8
Emergent Herbaceous Wetlands
Finally we have a nice table that includes the pixel values, a descriptive name of each land-use type, and the color commonly-used to portray that land-use in maps represented as a hexcode.
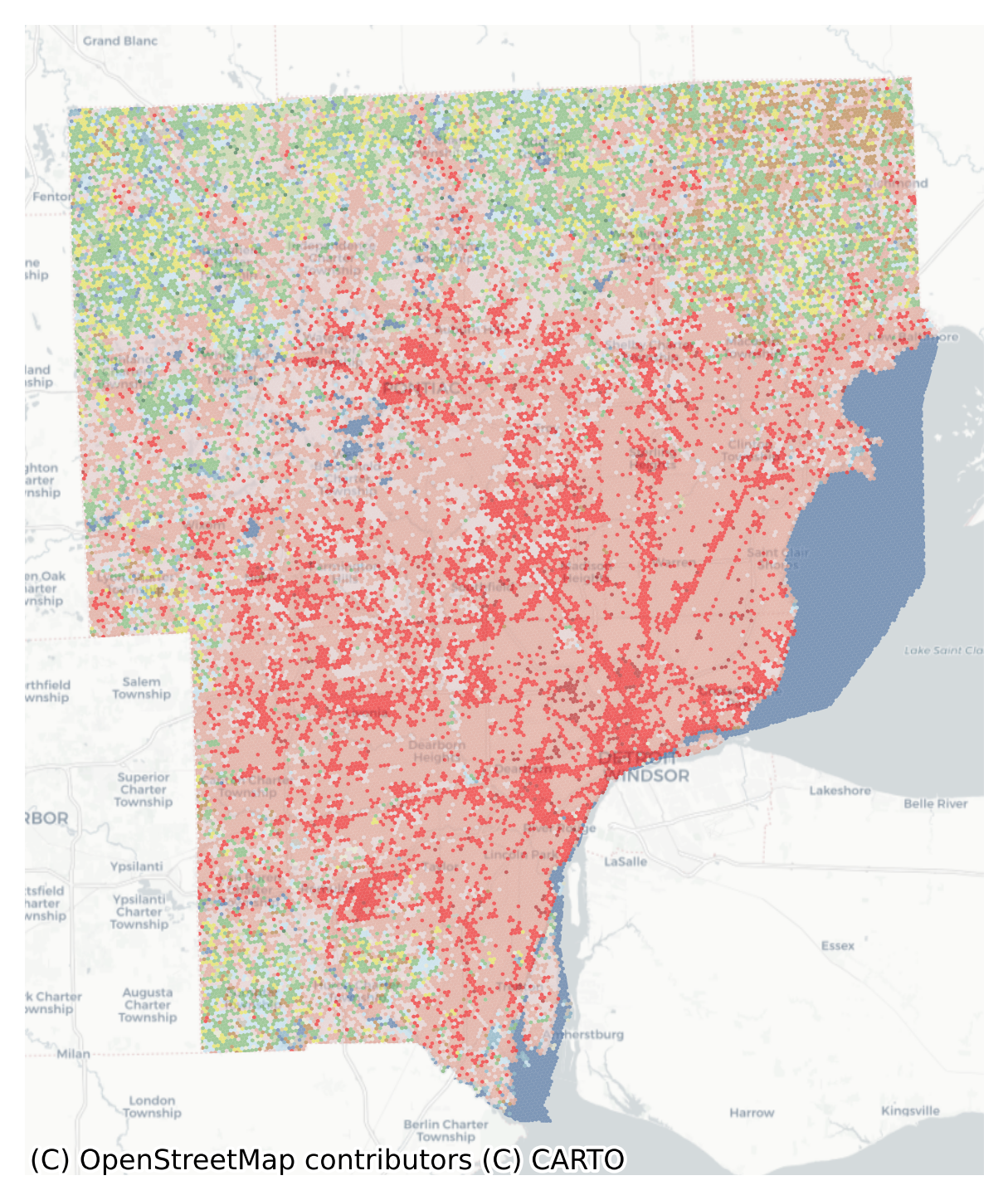
Land-Use Categories in Greater Detroit Shown in a Regular Hexgrid
With this data nicely formatted, we can read in multiple years of land-cover data, then convert them all to hexgrid polygons and assign the appropriate color and descriptive columns. For convenience we will also ignore scrubland and open water.
Code
nlcd_years = [2001, 2004, 2006, 2008, 2011, 2013, 2016]lulc_hexes = pd.concat(img_to_hex( hexes, f"/Users/knaaptime/Dropbox/projects/geosnap_data/nlcd/landcover/nlcd_landcover_{year}.tif", year) for year in nlcd_years)lulc_hexes = lulc_hexes.reset_index()lulc_hexes = lulc_hexes[lulc_hexes.value!='Shrub/Scrub']lulc_hexes = lulc_hexes[lulc_hexes.value!='Open Water']lulc_hexes['color'] = lulc_hexes.value.replace(color_mapper)
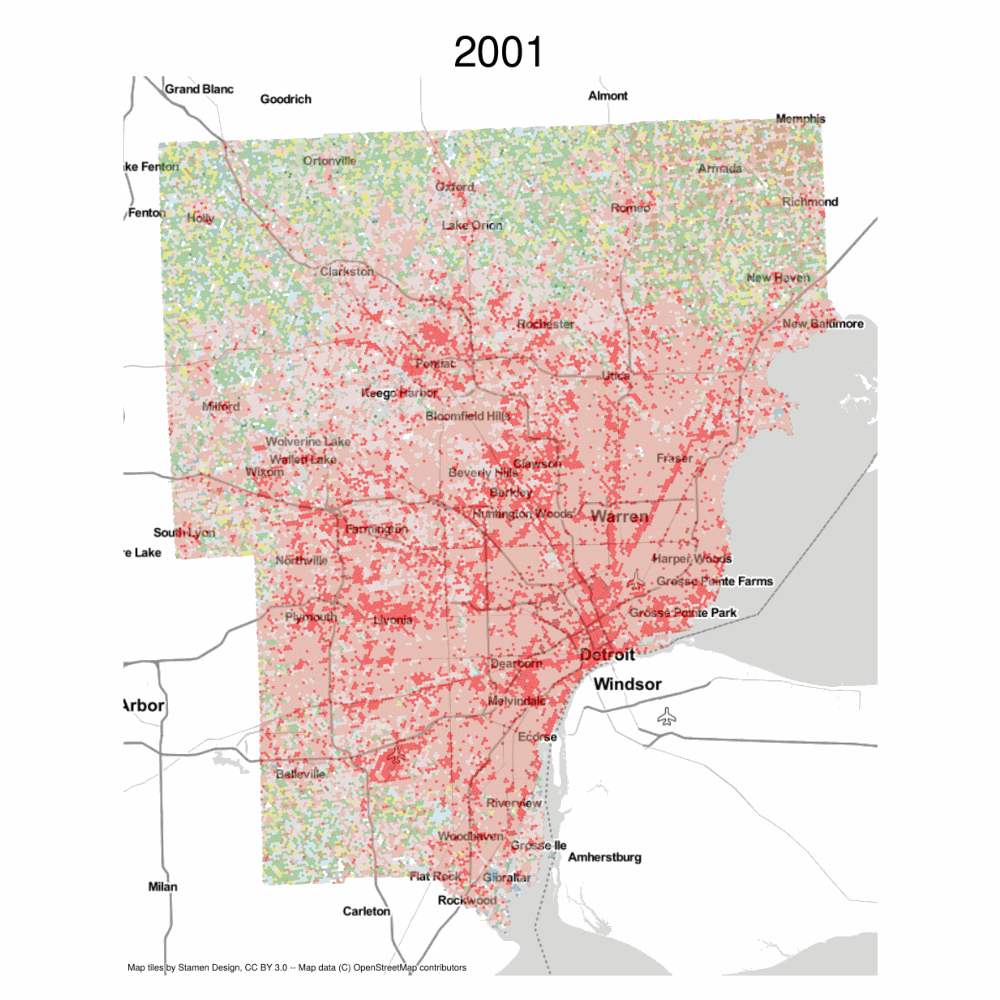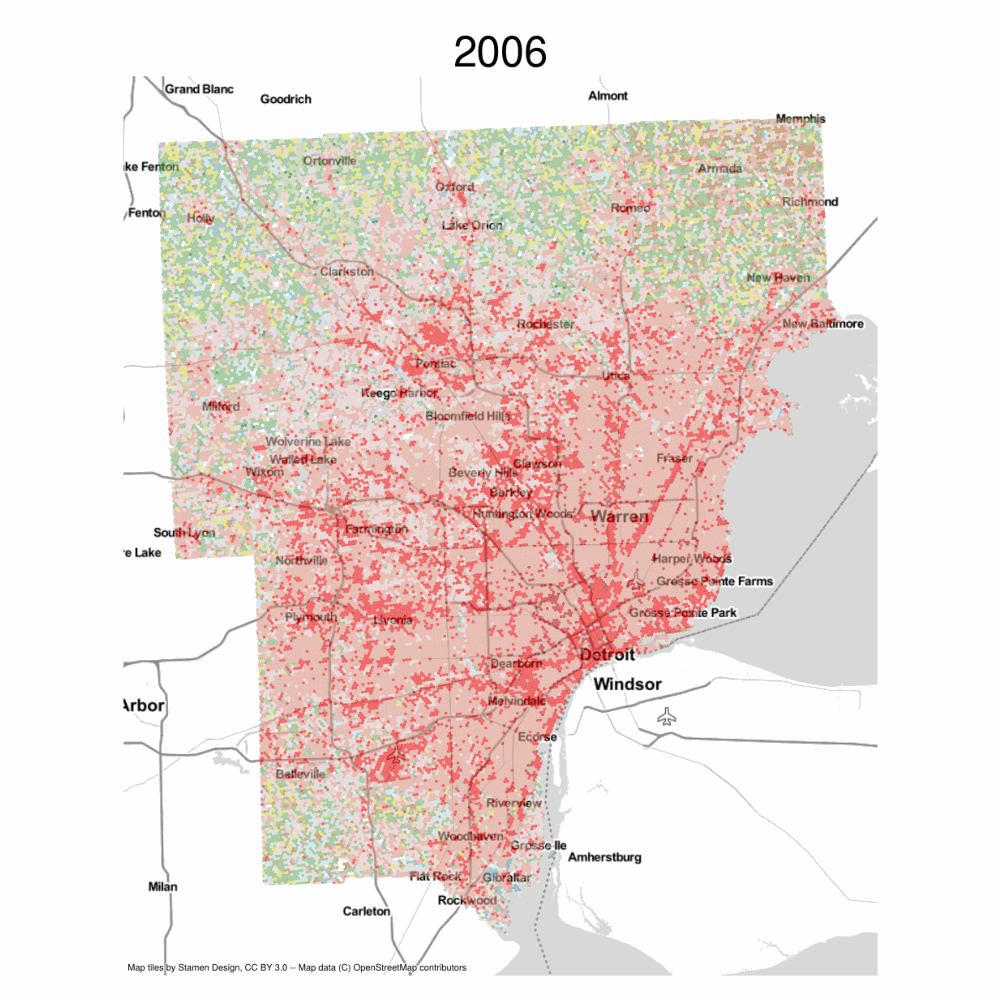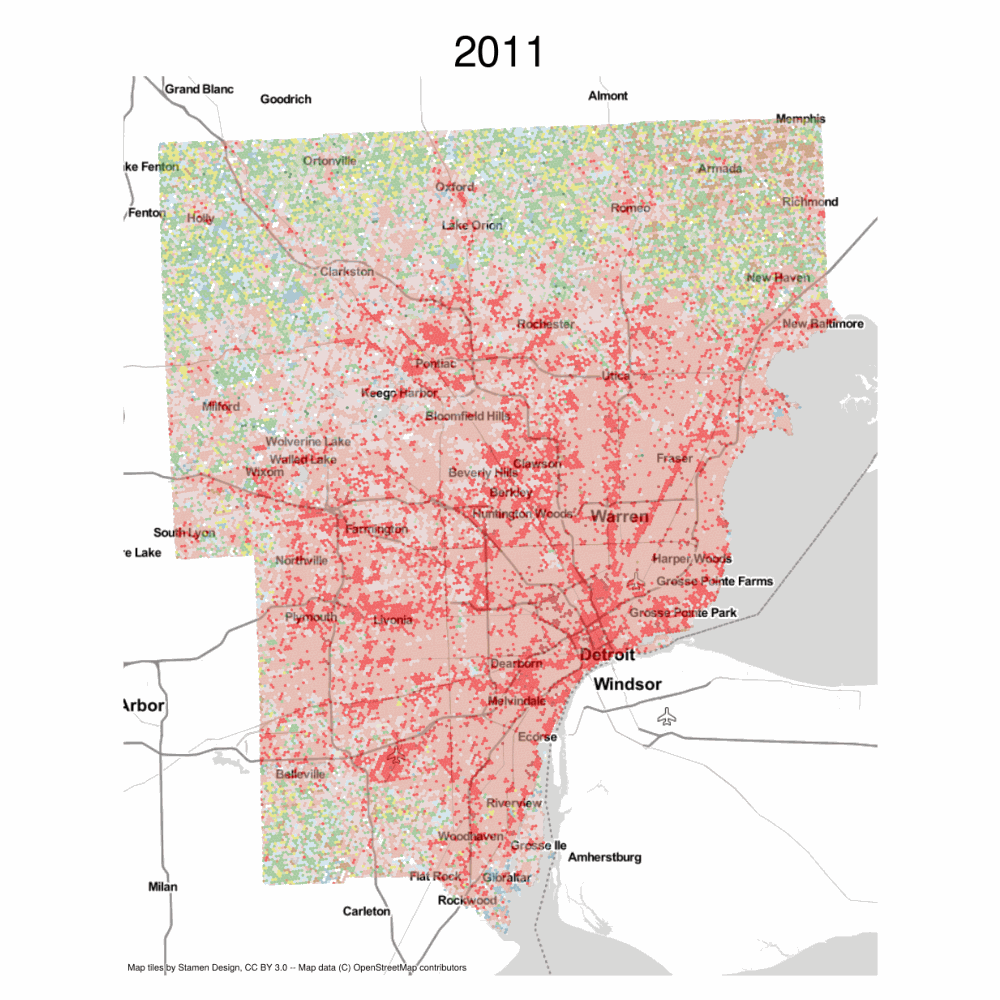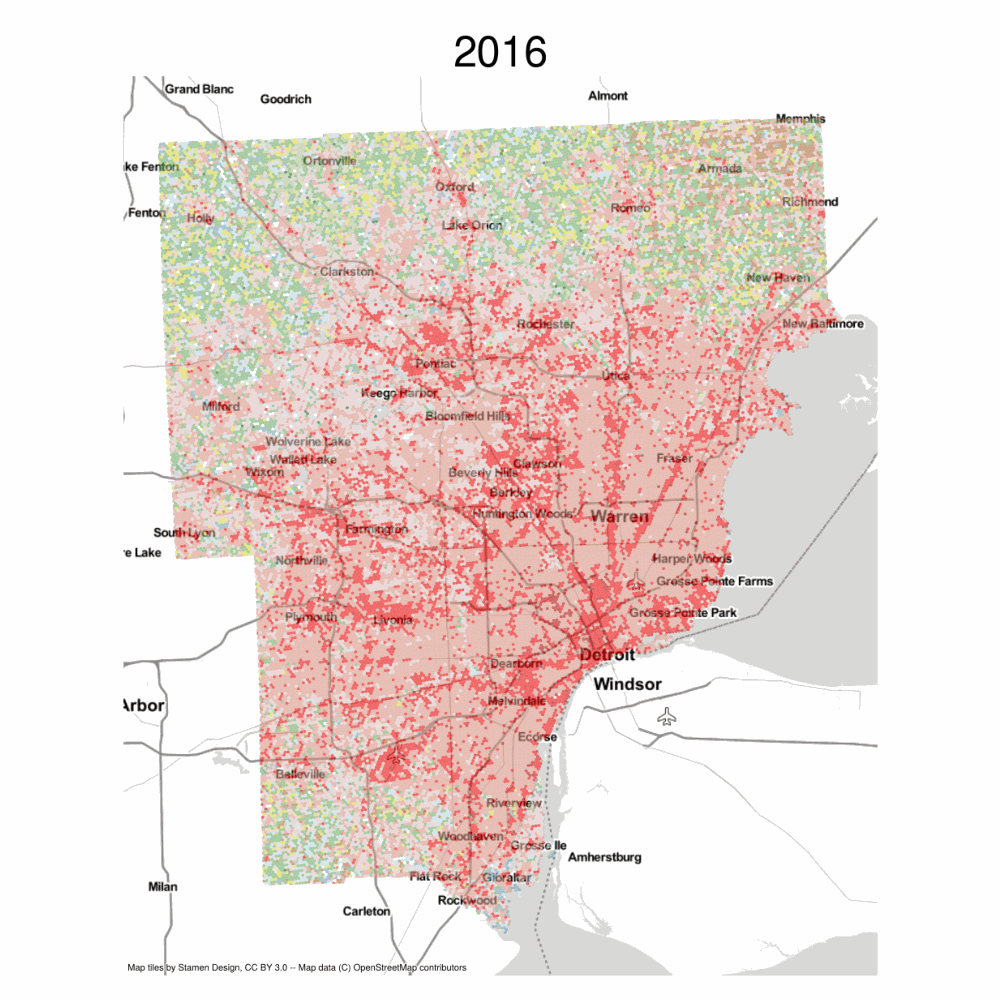
The result is a long-form geodataframe that stores land-use over time, which we can use to create a timeseries plot or an animated visualization.
These are the empirical transitions encoded in the NLCD data between 2001 and 2016, represented at by a slightly larger hexgrid.
Observed Transitions
26.2 Modeling Land-Use Change
Using geosnap and PySAL, we can look at these transitions more formally, modeling the change over time as a spatial Markov process. Using this framework, we can ask whether certain transitions are more likely than others given their spatial context. For example, is a piece of undeveloped land more likely to become developed if it’s neighbors have already been developed?
Code
sm = transition(lulc_hexes, unit_index='hex_id', cluster_col='value')
Code
type(sm)
giddy.markov.Spatial_Markov
Inference from the spatial Markov object shows the transitions are not random, but show different rates depending on the “neighborhood” of each observation
Code
sm.Q_p_value
np.float64(0.0)
Code
sm.LR_p_value
np.float64(0.0)
Plotting all the transition matrices can be daunting, but it provides a detailed look at how transition rates vary by context
We can see that barren land, for example, is much more likely to become developed when it’s neighbors are low-intensity developed (from top-left, see the second row, second column)
26.3 Simulating Future Land-Use
With these transition probabilities in hand (and the set of land uses in the last time period), we have all we need to simulate potential land uses in the future. First, we assume that the empirical transitions observed in prior time periods will remain static, and that only the prior time period influences the probability of transition between landuse types. Then, we can use the spatial context of each unit to select the proper transition matrix, and draw a new land-use type using the transition probabilities observed in the past.
Repeating this process for each unit in the study area gives a stochastic realization of land-use transitions; repeating this process for a range of years lets us look at a potential evolution of the region into the future. We could then change transition probabilities or manually edit land-uses in certain places (e.g. to simulate processes like urban development, sea-level rise, or a protective land-use policy) and see how those changes propagate through the system into the future.
Code
w = Queen.from_dataframe(lulc_hexes[lulc_hexes.year==2016].dropna().reset_index())
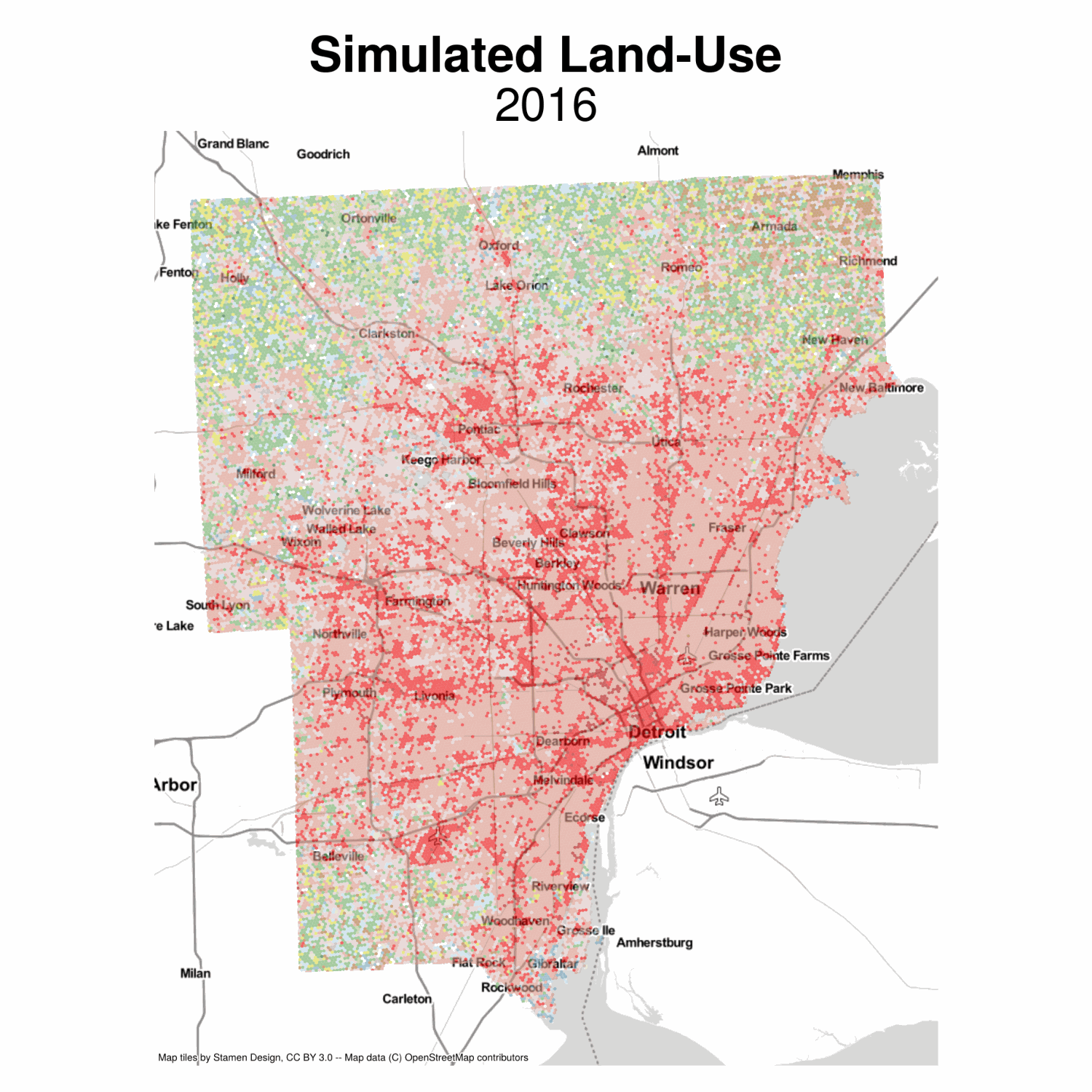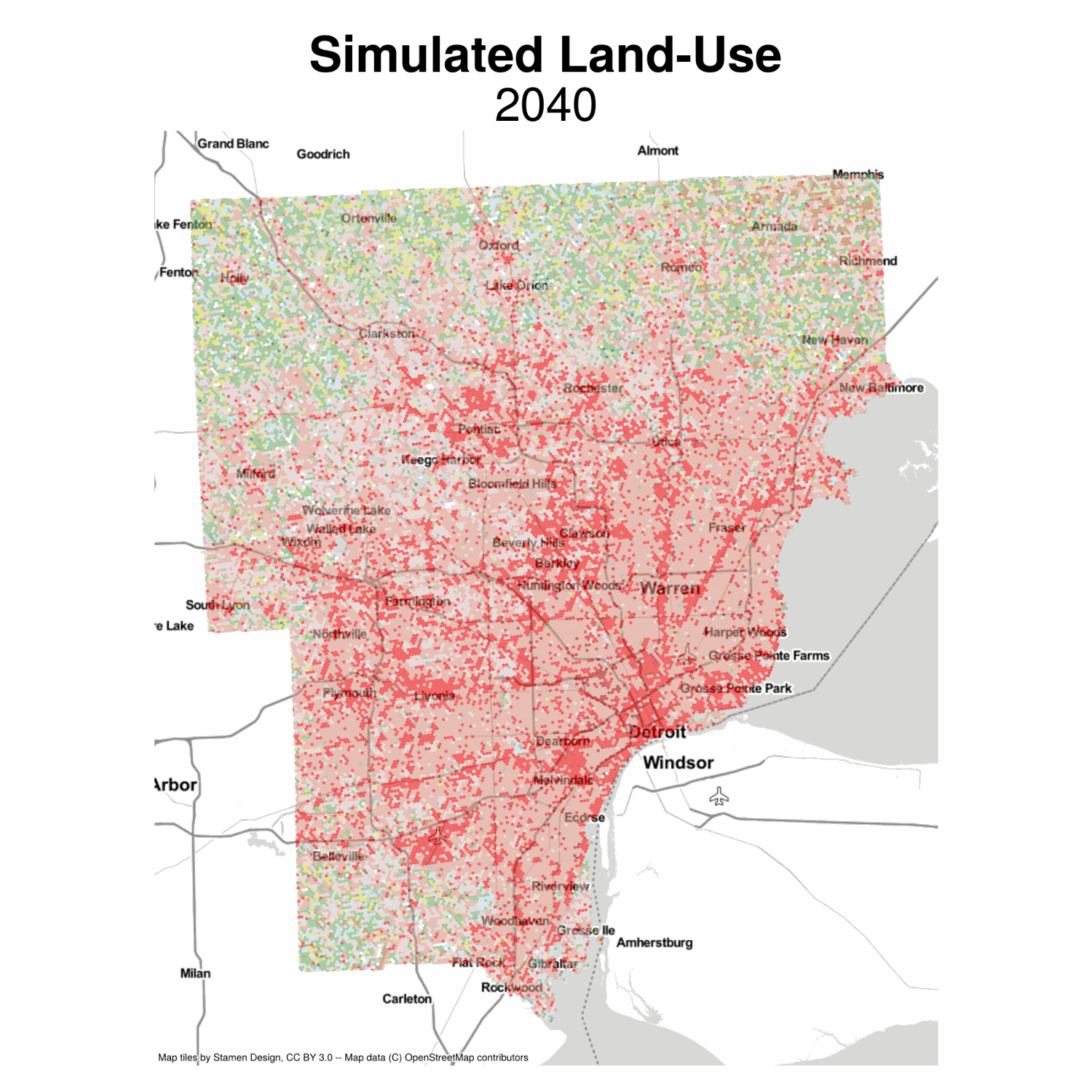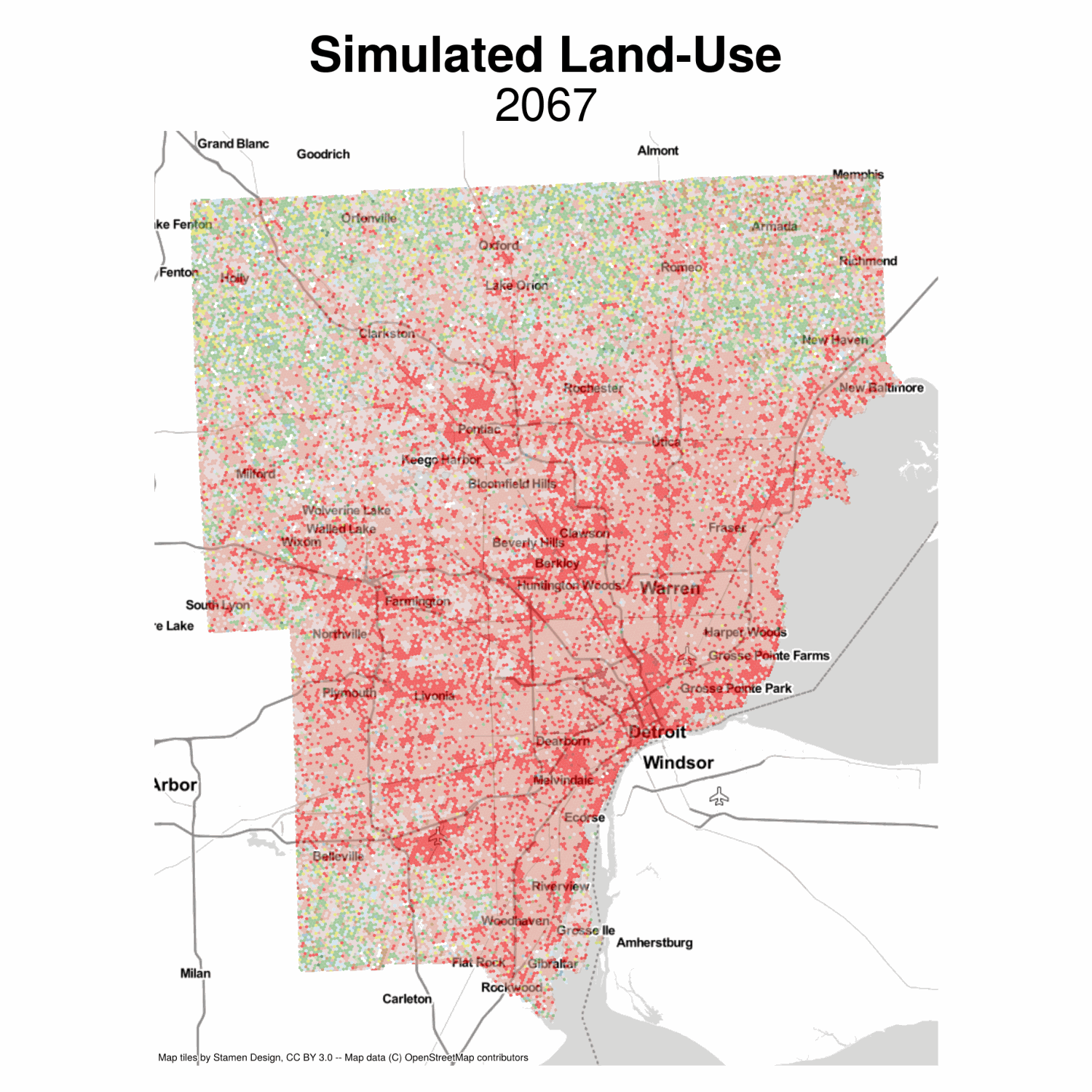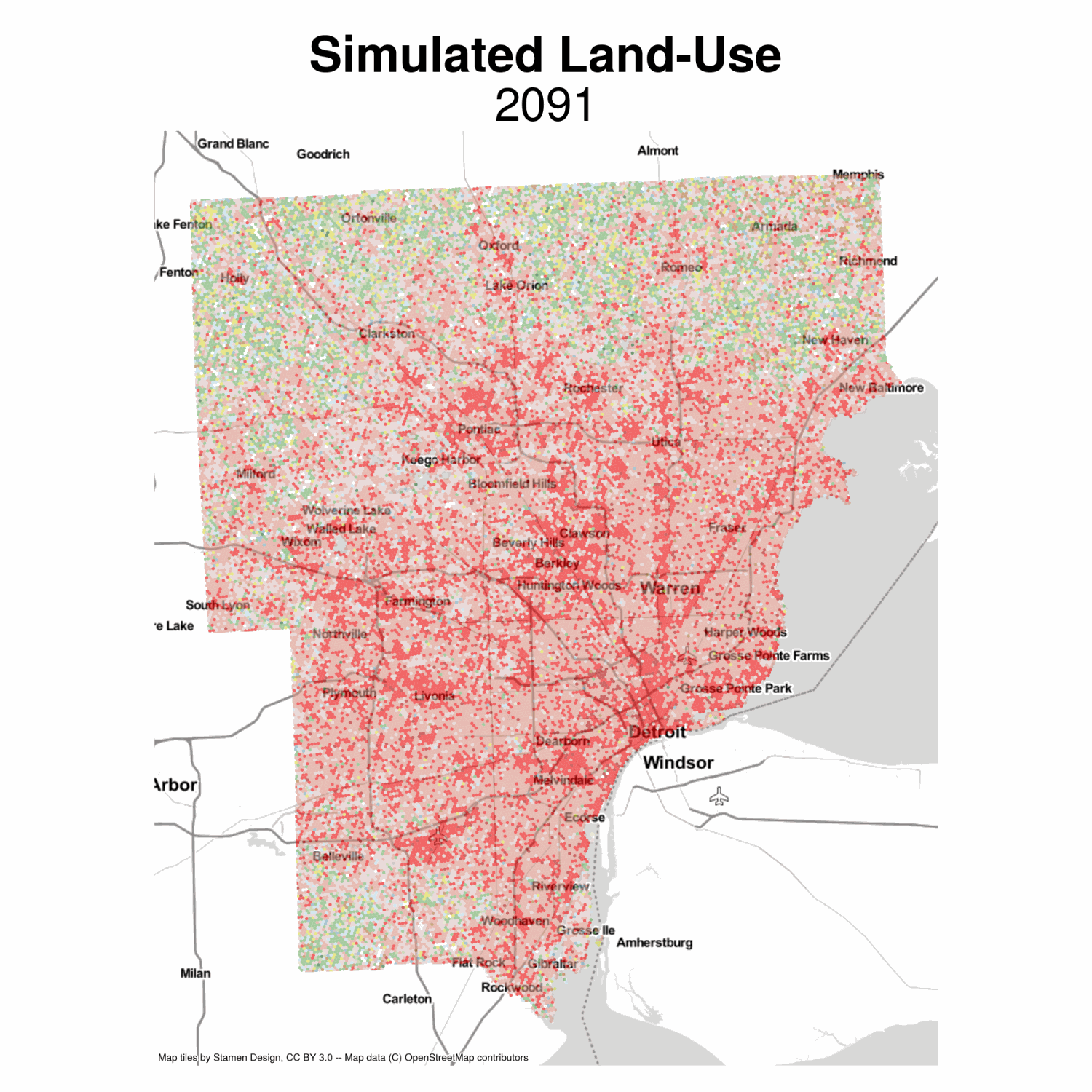
Now we can plot the simulated land-use moving into the future. This model is pretty naive, but the results seem plausible, with development growing outward from existing cores. We also get lots of infill (but the model isnt smart enough to know some places can’t be developed, etc). It would be fairly easy to include some additional restrictions that some observations are fixed because of policy or topology
Simulated Land Use
We can also quickly compute the share of land in each type and compare two time periods. Since the output is a regular grid, we just need to count the number of cells in each category without needing to actually look at the area
value
Barren Land (Rock/Sand/Clay) -0.001453
Cultivated Crops -0.008107
Deciduous Forest -0.023627
Developed High Intensity 0.006612
Developed, Low Intensity -0.002927
Developed, Medium Intensity 0.049739
Developed, Open Space 0.000400
Emergent Herbaceous Wetlands -0.002864
Evergreen Forest -0.000063
Grassland/Herbaceous -0.001748
Mixed Forest -0.001643
Pasture/Hay -0.006338
Woody Wetlands -0.007981
Name: proportion, dtype: float64
This would suggest a continued trend toward urbanization, with particularly large relative losses in deciduous forest. Low-intensity development is decreasing, but medium-intensity seems to be growing strongly. Following this analysis, some natural questions that arise include, what would it mean (in social, economic, environmental, etc.) terms to have a 5% increase in medium-intensity development and a 2.5% reduction in deciduous forest? What are the implications for climate change, anticipated housing growth, traffic congestion, change in tax revenue, and so on? And how might these conditions differ under a different scenario, such as one where we have alternative land regulations or urban growth constraints?
Avin, U. (2007). Using scenarios to make urban plans. Engaging the Future: Forecasts, Scenarios, Plans, and Projects, 103–134.
Avin, U., & Goodspeed, R. (2020). Using Exploratory Scenarios in Planning Practice: A Spectrum of Approaches. Journal of the American Planning Association, 0(0), 1–14. https://doi.org/10.1080/01944363.2020.1746688
Brail, R. K. (Ed.). (2008). Planning support systems for cities and regions. Lincoln Institute of Land Policy.
Chakraborty, A., Kaza, N., Knaap, G.-J., & Deal, B. (2011). Robust Plans and Contingent Plans: Scenario Planning for an Uncertain World. Journal of the American Planning Association, 77(3), 251–266. https://doi.org/10.1080/01944363.2011.582394
Chakraborty, A., & McMillan, A. (2015). Scenario Planning for Urban Planners: Toward a Practitioner’s Guide. Journal of the American Planning Association, 81(1), 18–29. https://doi.org/10.1080/01944363.2015.1038576
Dietzel, C., & Clarke, K. (2006). The effect of disaggregating land use categories in cellular automata during model calibration and forecasting. Computers, Environment and Urban Systems, 30(1), 78–101. https://doi.org/10.1016/j.compenvurbsys.2005.04.001
Guan, Q., & Clarke, K. C. (2010). A general-purpose parallel raster processing programming library test application using a geographic cellular automata model. International Journal of Geographical Information Science, 24(5), 695–722. https://doi.org/10.1080/13658810902984228
Jantz, C. A., Goetz, S. J., Donato, D., & Claggett, P. (2010). Designing and implementing a regional urban modeling system using the SLEUTH cellular urban model. Computers, Environment and Urban Systems, 34(1), 1–16. https://doi.org/10.1016/j.compenvurbsys.2009.08.003
Knaap, G., Engelberg, D., Avin, U., Erdogan, S., Ducca, F., Welch, T. F., Finio, N., Moeckel, R., & Shahumyan, H. (2020). Modeling Sustainability Scenarios in the Baltimore–Washington (DC) Region. Journal of the American Planning Association, 0(0), 1–14. https://doi.org/10.1080/01944363.2019.1680311