Code
import pandas as pd
import geopandas as gpd
import osmnx
from access import access as Access
import matplotlib.pyplot as plt
import urbanaccess as ua
import pandana as pdna
import osmnetimport pandas as pd
import geopandas as gpd
import osmnx
from access import access as Access
import matplotlib.pyplot as plt
import urbanaccess as ua
import pandana as pdna
import osmnet# https://www.cso.ie/en/census/census2016reports/census2016smallareapopulationstatistics/
ireland = gpd.read_file("../data/Small_Areas_Generalised_20m_-_OSi_National_Statistical_Boundaries_-_2015-shp/0d80d6a5-6314-4a4b-ac2f-09f3767f054b2020329-1-1rx3r8i.iy91.shp")ireland.plot()
ireland.GEOGID0 A047014001
1 A047034002
2 A047056001
3 A047300001
4 A067162001
...
18636 A267036002
18637 A267080007
18638 A267078024
18639 A267002009
18640 A267002008
Name: GEOGID, Length: 18641, dtype: objectireland.SMALL_AREA0 047014001
1 047034002
2 047056001
3 047300001
4 067162001
...
18636 267036002
18637 267080007
18638 267078023/267078024/267078025
18639 267002009
18640 267002008
Name: SMALL_AREA, Length: 18641, dtype: objectirish_data = pd.read_csv("../data/SAPS2016_SA2017.csv")irish_data['sa'] = irish_data.GEOGID.str[7:]irish_data.head()| GUID | GEOGID | GEOGDESC | T1_1AGE0M | T1_1AGE1M | T1_1AGE2M | T1_1AGE3M | T1_1AGE4M | T1_1AGE5M | T1_1AGE6M | ... | T15_2_Y | T15_2_N | T15_2_NS | T15_2_T | T15_3_B | T15_3_OTH | T15_3_N | T15_3_NS | T15_3_T | sa | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4c07d11e-11d3-851d-e053-ca3ca8c0ca7f | SA2017_017001001 | Small Area | 4 | 0 | 2 | 2 | 1 | 5 | 7 | ... | 97 | 27 | 4 | 128 | 83 | 20 | 23 | 2 | 128 | 017001001 |
| 1 | 4c07d11e-123a-851d-e053-ca3ca8c0ca7f | SA2017_017002001 | Small Area | 3 | 2 | 2 | 3 | 1 | 1 | 3 | ... | 86 | 26 | 2 | 114 | 72 | 18 | 23 | 1 | 114 | 017002001 |
| 2 | 4c07d11e-14b1-851d-e053-ca3ca8c0ca7f | SA2017_017002002 | Small Area | 4 | 2 | 4 | 3 | 4 | 4 | 4 | ... | 108 | 26 | 4 | 138 | 114 | 5 | 16 | 3 | 138 | 017002002 |
| 3 | 4c07d11e-14b2-851d-e053-ca3ca8c0ca7f | SA2017_017002003 | Small Area | 2 | 2 | 0 | 1 | 1 | 1 | 0 | ... | 80 | 19 | 4 | 103 | 74 | 13 | 15 | 1 | 103 | 017002003 |
| 4 | 4c07d11d-f709-851d-e053-ca3ca8c0ca7f | SA2017_017003001 | Small Area | 2 | 1 | 0 | 5 | 2 | 0 | 1 | ... | 55 | 24 | 4 | 83 | 50 | 10 | 21 | 2 | 83 | 017003001 |
5 rows × 803 columns
ireland = ireland.merge(irish_data, left_on='SMALL_AREA', right_on='sa', how='left')ireland['total_pop'] = ireland.T1_1AGETF + ireland.T1_1AGETM # not terribly sure about this data, so blindly assuming these are total femal and male colsireland = ireland[['sa', 'total_pop', 'geometry']]ireland.plot()
dublin_boundry = osmnx.geocoder.geocode_to_gdf('dublin, ireland', which_result=2)dublin_boundry.plot()
buffer = dublin_boundry.to_crs(29902).buffer(5000).to_crs(4326)buffer.plot()
dublin = ireland[ireland.representative_point().intersects(dublin_boundry.unary_union)]dublin.plot('total_pop', scheme='quantiles', k=10)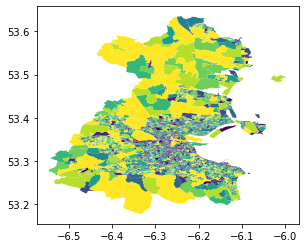
tuple(buffer.total_bounds)(-6.621839396013536, 53.13334561681906, -5.919187760125955, 53.67958772890603)dublin_net = osmnet.load.network_from_bbox(bbox=tuple(buffer.total_bounds))Requesting network data within bounding box from Overpass API in 4 request(s)
Posting to http://www.overpass-api.de/api/interpreter with timeout=180, "{'data': '[out:json][timeout:180];(way["highway"]["highway"!~"motor|proposed|construction|abandoned|platform|raceway"]["foot"!~"no"]["pedestrians"!~"no"](53.13334562,-6.62186632,53.41448425,-6.26827717);>;);out;'}"
Downloaded 38,162.3KB from www.overpass-api.de in 23.60 seconds
Posting to http://www.overpass-api.de/api/interpreter with timeout=180, "{'data': '[out:json][timeout:180];(way["highway"]["highway"!~"motor|proposed|construction|abandoned|platform|raceway"]["foot"!~"no"]["pedestrians"!~"no"](53.40691485,-6.62186632,53.68010174,-6.25061853);>;);out;'}"
Downloaded 8,304.2KB from www.overpass-api.de in 4.03 seconds
Posting to http://www.overpass-api.de/api/interpreter with timeout=180, "{'data': '[out:json][timeout:180];(way["highway"]["highway"!~"motor|proposed|construction|abandoned|platform|raceway"]["foot"!~"no"]["pedestrians"!~"no"](53.39841263,-6.26827717,53.68010174,-5.91918776);>;);out;'}"
Downloaded 9,118.2KB from www.overpass-api.de in 5.14 seconds
Posting to http://www.overpass-api.de/api/interpreter with timeout=180, "{'data': '[out:json][timeout:180];(way["highway"]["highway"!~"motor|proposed|construction|abandoned|platform|raceway"]["foot"!~"no"]["pedestrians"!~"no"](53.13334562,-6.28563978,53.40691485,-5.91918776);>;);out;'}"
Downloaded 31,995.0KB from www.overpass-api.de in 21.13 seconds
Downloaded OSM network data within bounding box from Overpass API in 4 request(s) and 55.46 seconds
59,959 duplicate records removed. Took 4.47 seconds
Returning OSM data with 588,888 nodes and 106,318 ways...
Edge node pairs completed. Took 88.54 seconds
Returning processed graph with 131,215 nodes and 173,159 edges...
Completed OSM data download and Pandana node and edge table creation in 151.19 secondsloaded_feeds = ua.gtfsfeed_to_df("../data/irish_gtfs/")GTFS text file header whitespace check completed. Took 1.07 seconds
--------------------------------
Processing GTFS feed: gtfs1
The unique agency id: go-ahead was generated using the name of the agency in the agency.txt file.
Unique agency id operation complete. Took 0.02 seconds
Unique GTFS feed id operation complete. Took 0.00 seconds
Appended route type to stops
Appended route type to stop_times
--------------------------------
--------------------------------
Processing GTFS feed: gtfs
The unique agency id: dublin_bus was generated using the name of the agency in the agency.txt file.
Unique agency id operation complete. Took 0.04 seconds
Unique GTFS feed id operation complete. Took 0.01 seconds
Appended route type to stops
Appended route type to stop_times
--------------------------------
--------------------------------
Processing GTFS feed: gtfs2
The unique agency id: luas was generated using the name of the agency in the agency.txt file.
Unique agency id operation complete. Took 0.01 seconds
Unique GTFS feed id operation complete. Took 0.00 seconds
Appended route type to stops
Appended route type to stop_times
--------------------------------
Successfully converted ['departure_time'] to seconds past midnight and appended new columns to stop_times. Took 5.16 seconds
3 GTFS feed file(s) successfully read as dataframes:
gtfs1
gtfs
gtfs2
Took 11.70 secondsua.create_transit_net(gtfsfeeds_dfs=loaded_feeds,
day='monday',
timerange=['07:00:00', '10:00:00'],
calendar_dates_lookup=None)Using calendar to extract service_ids to select trips.
12 service_ids were extracted from calendar
16,108 trip(s) 32.47 percent of 49,605 total trip records were found in calendar for GTFS feed(s): ['gtfs1', 'gtfs', 'gtfs2']
NOTE: If you expected more trips to have been extracted and your GTFS feed(s) have a calendar_dates file, consider utilizing the calendar_dates_lookup parameter in order to add additional trips based on information inside of calendar_dates. This should only be done if you know the corresponding GTFS feed is using calendar_dates instead of calendar to specify service_ids. When in doubt do not use the calendar_dates_lookup parameter.
16,108 of 49,605 total trips were extracted representing calendar day: monday. Took 0.07 seconds
There are no departure time records missing from trips following monday schedule. There are no records to interpolate.
Difference between stop times has been successfully calculated. Took 2.36 seconds
Stop times from 07:00:00 to 10:00:00 successfully selected 118,787 records out of 774,030 total records (15.35 percent of total). Took 0.22 seconds
Starting transformation process for 3,026 total trips...
stop time table transformation to Pandana format edge table completed. Took 4.56 seconds
Time conversion completed: seconds converted to minutes.
6,109 of 6,300 records selected from stops. Took 0.01 seconds
stop time table transformation to Pandana format node table completed. Took 0.00 seconds
route type successfully joined to transit edges. Took 2.65 seconds
route id successfully joined to transit edges. Took 0.08 seconds
Successfully created transit network. Took 12.31 seconds<urbanaccess.network.urbanaccess_network at 0x7f30c34428d0>ua_net = ua.ua_networkua_osm = ua.create_osm_net(osm_edges=dublin_net[1],
osm_nodes=dublin_net[0],
travel_speed_mph=3)Created OSM network with travel time impedance using a travel speed of 3 MPH. Took 0.01 secondsua.integrate_network(urbanaccess_network=ua_net,
headways=False
)Loaded UrbanAccess network components comprised of:
Transit: 6,109 nodes and 115,761 edges;
OSM: 131,215 nodes and 173,159 edges
Connector edges between the OSM and transit network nodes successfully completed. Took 1.78 seconds
Edge and node tables formatted for Pandana with integer node ids: id_int, to_int, and from_int. Took 2.01 seconds
Network edge and node network integration completed successfully resulting in a total of 137,324 nodes and 301,138 edges:
Transit: 6,109 nodes 115,761 edges;
OSM: 131,215 nodes 173,159 edges; and
OSM/Transit connector: 12,218 edges.<urbanaccess.network.urbanaccess_network at 0x7f30c34428d0>combined_net = pdna.Network(ua_net.net_nodes["x"],
ua_net.net_nodes["y"],
ua_net.net_edges["from_int"],
ua_net.net_edges["to_int"],
ua_net.net_edges[["weight"]])buffer = buffer.to_frame()buffer.columns = ['geometry']buffer.total_boundsarray([-6.6218394 , 53.13334562, -5.91918776, 53.67958773])buffer.info()<class 'geopandas.geodataframe.GeoDataFrame'>
RangeIndex: 1 entries, 0 to 0
Data columns (total 1 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 geometry 1 non-null geometry
dtypes: geometry(1)
memory usage: 136.0 byteshealth = osmnx.pois.pois_from_polygon(buffer.unary_union, tags={'amenity':['doctor', 'hospital'],
'healthcare': True})health['care'] = 1health.plot()
import healthacc as hadublin = dublin.groupby('sa').first().reset_index()adjlist = ha.compute_travel_cost_adjlist(dublin, dublin, combined_net, reindex_dest='sa', reindex_orig='sa')adjlist = adjlist.replace(0.0,1.0) # gravity weights dont like 0 travel timejoined = gpd.sjoin(dublin, health[['geometry', 'care']], op='intersects', how='left').groupby('sa').sum()['care']/home/knaaptime/anaconda3/envs/healthacc/lib/python3.7/site-packages/ipykernel_launcher.py:1: UserWarning: CRS mismatch between the CRS of left geometries and the CRS of right geometries.
Use `to_crs()` to reproject one of the input geometries to match the CRS of the other.
Left CRS: None
Right CRS: EPSG:4326
"""Entry point for launching an IPython kernel.dublin = dublin.merge(joined, left_on='sa', right_index=True)ac = Access(demand_df = dublin,
demand_index = 'sa',
demand_value = 'total_pop',
supply_df = dublin,
supply_index = 'sa',
cost_df=adjlist,
cost_origin='origin',
cost_dest='destination',
cost_name='cost',
supply_value='care',
neighbor_cost_df = adjlist,
neighbor_cost_origin = 'origin',
neighbor_cost_dest = 'destination',
neighbor_cost_name = 'cost'
)from access import weights as acweightsgravity = acweights.gravity(scale = 60, alpha = -1)
gaussian = acweights.gaussian(60)#ac.raam(name="raam", tau=60); # not sure why raam doesnt workac.two_stage_fca(name = "2sfca", max_cost = 30,)
ac.enhanced_two_stage_fca(name = "g2sfca", weight_fn = gravity)
ac.three_stage_fca(name = "3sfca")
ac.weighted_catchment(name = "gravity", weight_fn = gravity)
ac.weighted_catchment(name = "gaussian", weight_fn = gaussian)
ac.fca_ratio(name = "fca30", max_cost = 30)
ac.fca_ratio(name = "fca60", max_cost = 60) | fca60_care | |
|---|---|
| sa | |
| 267001001 | 0.000758 |
| 267001002 | 0.000758 |
| 267001003 | 0.000761 |
| 267001004 | 0.000761 |
| 267001005 | 0.000762 |
| ... | ... |
| 268162014 | 0.000757 |
| 268162015 | NaN |
| 268162016 | 0.000758 |
| 268162017 | 0.000757 |
| 268162018 | 0.000760 |
4881 rows × 1 columns
results = dublin[['sa', 'geometry']].merge(ac.access_df, left_on='sa', right_index=True)import numpy as npresults = results.replace([np.inf, -np.inf] ,np.nan)results.crs = 4326results = results.to_crs(3857)import matplotlib.pyplot as pltimport contextily as ctxfor i in ['gravity_care', 'gaussian_care',
'2sfca_care',
'g2sfca_care', '3sfca_care',
'fca30_care', 'fca60_care']:
fig, ax=plt.subplots( figsize=(10,20))
results.dropna(subset=[i]).plot(column=i, scheme='quantiles', cmap='magma_r', k=12, ax=ax, alpha=0.6)
#health.to_crs(3857).plot(ax=ax, color='red')
ctx.add_basemap(ax, url=ctx.providers.Stamen.TonerLite)
ax.set_title(i)
ax.axis('off')
plt.savefig(f"../figures/dublin_{i}.png", dpi=400)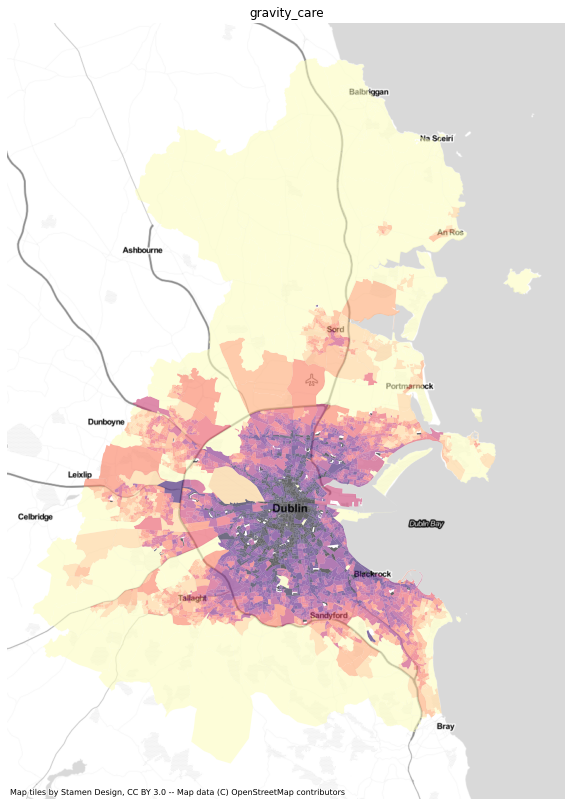
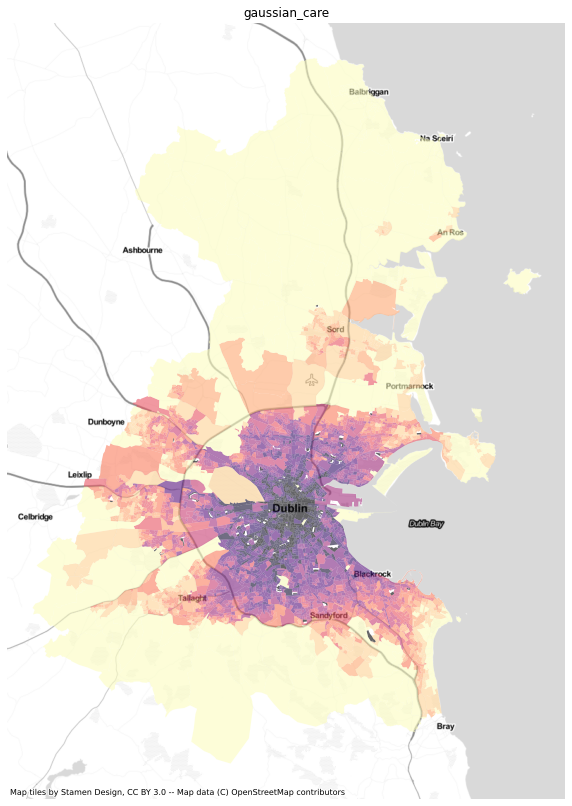
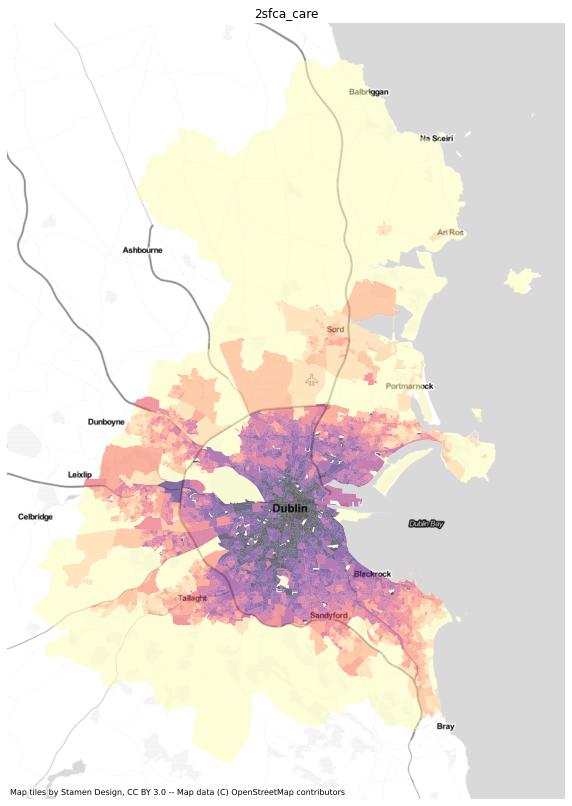
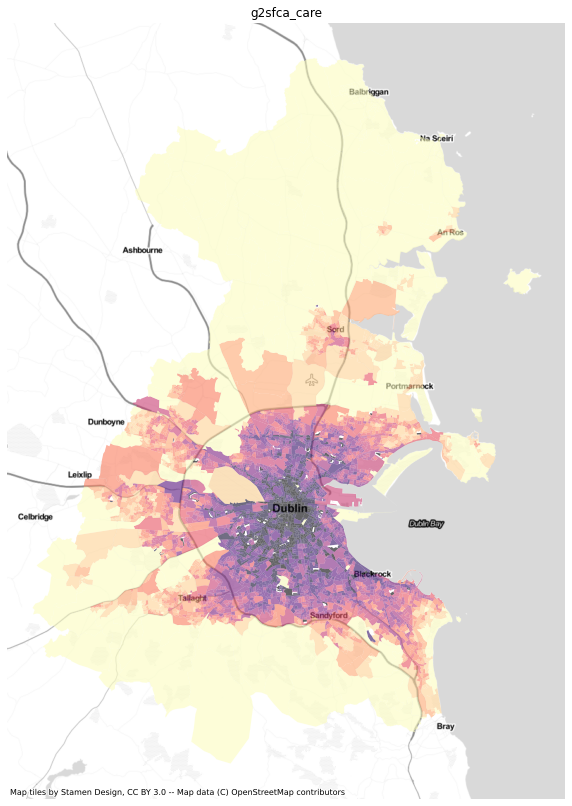
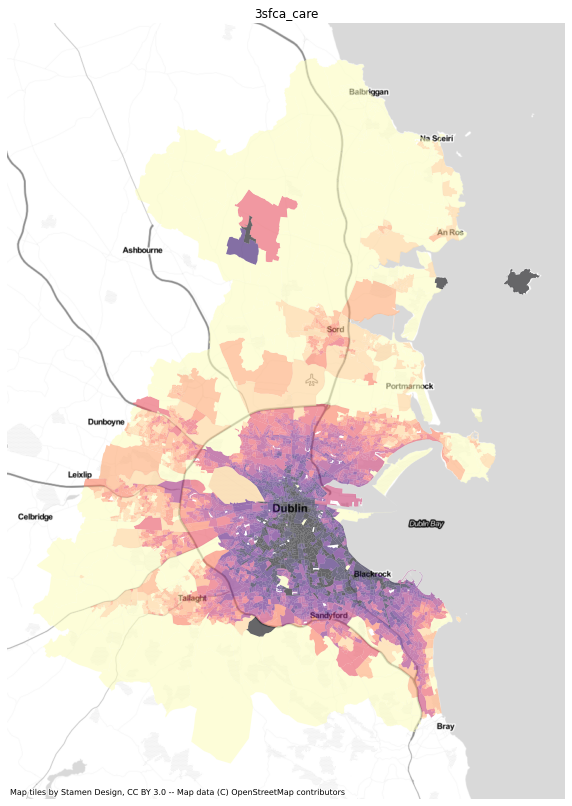
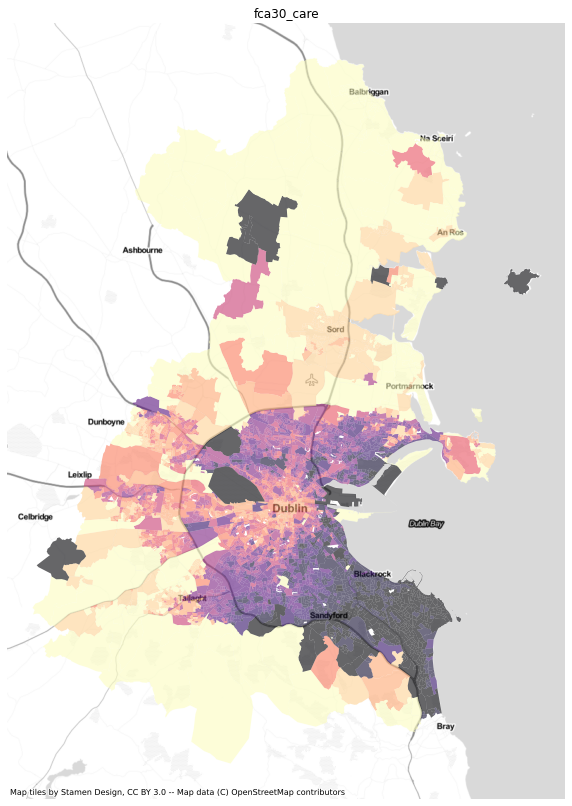
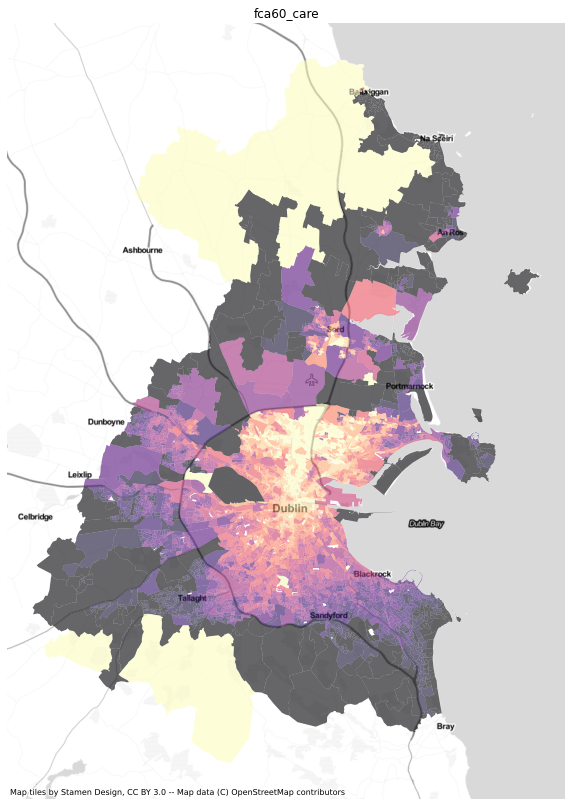
![]()
:::